
27 Jul 2025


ByteDance Seed introduced BAGEL, an open-source unified multimodal foundation model trained on trillions of interleaved text, image, and video tokens. This model demonstrates emergent reasoning abilities and achieves state-of-the-art performance among open-source alternatives, narrowing the capability gap with leading proprietary systems.

02 Feb 2024

Three-dimensional coronary magnetic resonance angiography (CMRA) demands
reconstruction algorithms that can significantly suppress the artifacts from a
heavily undersampled acquisition. While unrolling-based deep reconstruction
methods have achieved state-of-the-art performance on 2D image reconstruction,
their application to 3D reconstruction is hindered by the large amount of
memory needed to train an unrolled network. In this study, we propose a
memory-efficient deep compressed sensing method by employing a sparsifying
transform based on a pre-trained artifact estimation network. The motivation is
that the artifact image estimated by a well-trained network is sparse when the
input image is artifact-free, and less sparse when the input image is
artifact-affected. Thus, the artifact-estimation network can be used as an
inherent sparsifying transform. The proposed method, named De-Aliasing
Regularization based Compressed Sensing (DARCS), was compared with a
traditional compressed sensing method, de-aliasing generative adversarial
network (DAGAN), model-based deep learning (MoDL), and plug-and-play for
accelerations of 3D CMRA. The results demonstrate that the proposed method
improved the reconstruction quality relative to the compared methods by a large
margin. Furthermore, the proposed method well generalized for different
undersampling rates and noise levels. The memory usage of the proposed method
was only 63% of that needed by MoDL. In conclusion, the proposed method
achieves improved reconstruction quality for 3D CMRA with reduced memory
burden.

08 Dec 2025
Utilizing multi-band JWST observations, this research reveals that high-redshift submillimeter galaxies primarily form through secular evolution and internal processes rather than major mergers, uncovering a significant population of central stellar structures that do not conform to established local galaxy classifications.

08 Dec 2025


Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.

16 Oct 2025
Researchers at the Chinese Academy of Sciences developed QDepth-VLA, a framework that enhances Vision-Language-Action (VLA) models with robust 3D geometric understanding through quantized depth prediction as auxiliary supervision. This approach improves performance on fine-grained robotic manipulation tasks, achieving up to 29.7% higher success rates on complex simulated tasks and 20.0% gains in real-world pick-and-place scenarios compared to existing baselines.

11 Jun 2024

Developed by Huawei Co., Ltd., CODER introduces a multi-agent framework guided by pre-defined task graphs to automate GitHub issue resolution. The system achieved a 28.33% resolved rate on SWE-bench lite, establishing a new state-of-the-art for the benchmark.

24 Nov 2025


VideoChat-M1 introduces a multi-agent framework that employs Collaborative Policy Planning and Multi-Agent Reinforcement Learning to dynamically adapt tool invocation strategies for video understanding. The system achieves state-of-the-art performance across eight challenging benchmarks, including long video QA and spatial intelligence, outperforming GPT-4o by 15.6% on LongVideoBench and Gemini 1.5 Pro by 26.5% on VSIBench, while significantly reducing inference time and frame processing.

15 Oct 2025
Recent Large Language Models (LLMs) have demonstrated remarkable profi- ciency in code generation. However, their ability to create complex visualiza- tions for scaled and structured data remains largely unevaluated and underdevel- oped. To address this gap, we introduce PlotCraft, a new benchmark featuring 1k challenging visualization tasks that cover a wide range of topics, such as fi- nance, scientific research, and sociology. The benchmark is structured around seven high-level visualization tasks and encompasses 48 distinct chart types. Cru- cially, it is the first to systematically evaluate both single-turn generation and multi-turn refinement across a diverse spectrum of task complexities. Our com- prehensive evaluation of 23 leading LLMs on PlotCraft reveals obvious per- formance deficiencies in handling sophisticated visualization tasks. To bridge this performance gap, we develope SynthVis-30K, a large-scale, high-quality dataset of complex visualization code synthesized via a collaborative agent frame- work. Building upon this dataset, we develope PlotCraftor, a novel code gener- ation model that achieves strong capabilities in complex data visualization with a remarkably small size. Across VisEval, PandasPlotBench, and our proposed PlotCraft, PlotCraftor shows performance comparable to that of leading propri- etary approaches. Especially, on hard task, Our model achieves over 50% per- formance improvement. We will release the benchmark, dataset, and code at this https URL.

17 Oct 2025
Open world Machine Learning (OWML) aims to develop intelligent systems capable of recognizing known categories, rejecting unknown samples, and continually learning from novel information. Despite significant progress in open set recognition, novelty detection, and continual learning, the field still lacks a unified theoretical foundation that can quantify uncertainty, characterize information transfer, and explain learning adaptability in dynamic, nonstationary environments. This paper presents a comprehensive review of information theoretic approaches in open world machine learning, emphasizing how core concepts such as entropy, mutual information, and Kullback Leibler divergence provide a mathematical language for describing knowledge acquisition, uncertainty suppression, and risk control under open world conditions. We synthesize recent studies into three major research axes: information theoretic open set recognition enabling safe rejection of unknowns, information driven novelty discovery guiding new concept formation, and information retentive continual learning ensuring stable long term adaptation. Furthermore, we discuss theoretical connections between information theory and provable learning frameworks, including PAC Bayes bounds, open-space risk theory, and causal information flow, to establish a pathway toward provable and trustworthy open world intelligence. Finally, the review identifies key open problems and future research directions, such as the quantification of information risk, development of dynamic mutual information bounds, multimodal information fusion, and integration of information theory with causal reasoning and world model learning.

01 Oct 2025


While Large Language Models (LLMs) have become the predominant paradigm for automated code generation, current single-model approaches fundamentally ignore the heterogeneous computational strengths that different models exhibit across programming languages, algorithmic domains, and development stages. This paper challenges the single-model convention by introducing a multi-stage, performance-guided orchestration framework that dynamically routes coding tasks to the most suitable LLMs within a structured generate-fix-refine workflow. Our approach is grounded in a comprehensive empirical study of 17 state-of-the-art LLMs across five programming languages (Python, Java, C++, Go, and Rust) using HumanEval-X benchmark. The study, which evaluates both functional correctness and runtime performance metrics (execution time, mean/max memory utilization, and CPU efficiency), reveals pronounced performance heterogeneity by language, development stage, and problem category. Guided by these empirical insights, we present PerfOrch, an LLM agent that orchestrates top-performing LLMs for each task context through stage-wise validation and rollback mechanisms. Without requiring model fine-tuning, PerfOrch achieves substantial improvements over strong single-model baselines: average correctness rates of 96.22% and 91.37% on HumanEval-X and EffiBench-X respectively, surpassing GPT-4o's 78.66% and 49.11%. Beyond correctness gains, the framework delivers consistent performance optimizations, improving execution time for 58.76% of problems with median speedups ranging from 17.67% to 27.66% across languages on two benchmarks. The framework's plug-and-play architecture ensures practical scalability, allowing new LLMs to be profiled and integrated seamlessly, thereby offering a paradigm for production-grade automated software engineering that adapts to the rapidly evolving generative AI landscape.
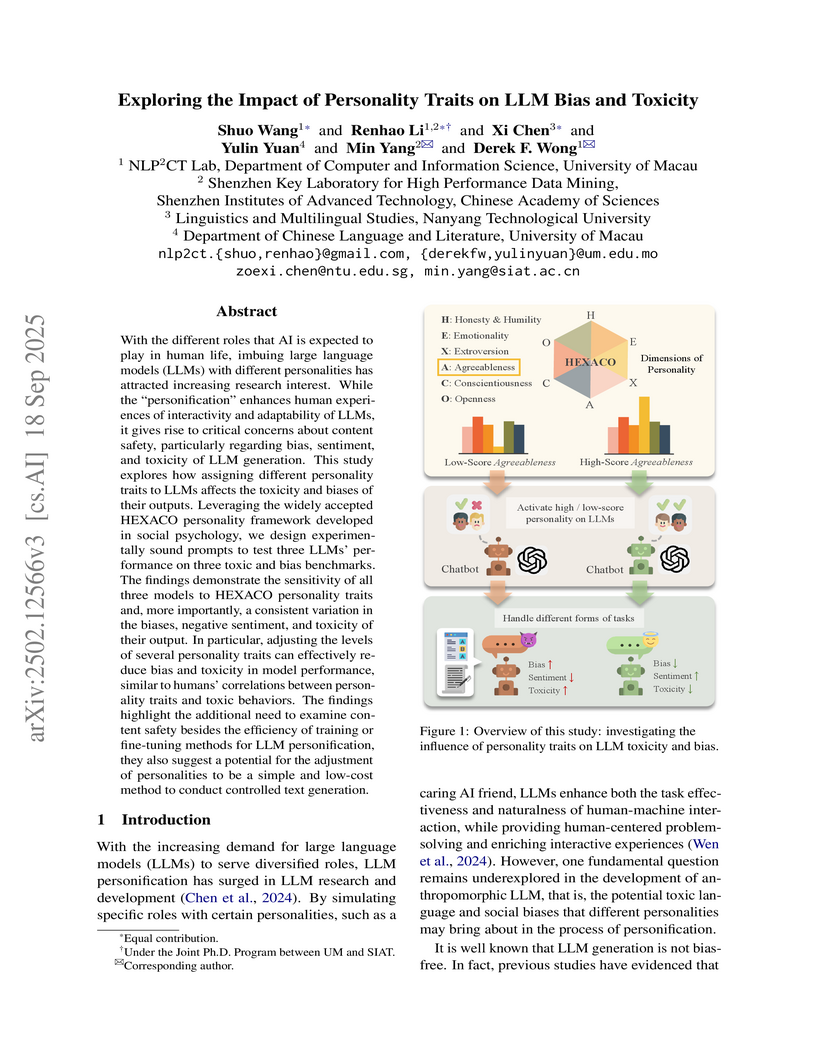
18 Sep 2025


With the different roles that AI is expected to play in human life, imbuing large language models (LLMs) with different personalities has attracted increasing research interests. While the "personification" enhances human experiences of interactivity and adaptability of LLMs, it gives rise to critical concerns about content safety, particularly regarding bias, sentiment and toxicity of LLM generation. This study explores how assigning different personality traits to LLMs affects the toxicity and biases of their outputs. Leveraging the widely accepted HEXACO personality framework developed in social psychology, we design experimentally sound prompts to test three LLMs' performance on three toxic and bias benchmarks. The findings demonstrate the sensitivity of all three models to HEXACO personality traits and, more importantly, a consistent variation in the biases, negative sentiment and toxicity of their output. In particular, adjusting the levels of several personality traits can effectively reduce bias and toxicity in model performance, similar to humans' correlations between personality traits and toxic behaviors. The findings highlight the additional need to examine content safety besides the efficiency of training or fine-tuning methods for LLM personification. They also suggest a potential for the adjustment of personalities to be a simple and low-cost method to conduct controlled text generation.

01 Apr 2025

Researchers developed LARF (Let AI Read First), an AI-powered system leveraging GPT-4 to annotate important information in texts with visual cues, improving reading performance and subjective experience for individuals with dyslexia, particularly those with more severe conditions. The system enhanced objective detail retrieval and comprehension while preserving original content.

07 May 2025

Smart traffic lights in intelligent transportation systems (ITSs) are envisioned to greatly increase traffic efficiency and reduce congestion. Deep reinforcement learning (DRL) is a promising approach to adaptively control traffic lights based on the real-time traffic situation in a road network. However, conventional methods may suffer from poor scalability. In this paper, we investigate deep reinforcement learning to control traffic lights, and both theoretical analysis and numerical experiments show that the intelligent behavior ``greenwave" (i.e., a vehicle will see a progressive cascade of green lights, and not have to brake at any intersection) emerges naturally a grid road network, which is proved to be the optimal policy in an avenue with multiple cross streets. As a first step, we use two DRL algorithms for the traffic light control problems in two scenarios. In a single road intersection, we verify that the deep Q-network (DQN) algorithm delivers a thresholding policy; and in a grid road network, we adopt the deep deterministic policy gradient (DDPG) algorithm. Secondly, numerical experiments show that the DQN algorithm delivers the optimal control, and the DDPG algorithm with passive observations has the capability to produce on its own a high-level intelligent behavior in a grid road network, namely, the ``greenwave" policy emerges. We also verify the ``greenwave" patterns in a grid road network. Thirdly, the ``greenwave" patterns demonstrate that DRL algorithms produce favorable solutions since the ``greenwave" policy shown in experiment results is proved to be optimal in a specified traffic model (an avenue with multiple cross streets). The delivered policies both in a single road intersection and a grid road network demonstrate the scalability of DRL algorithms.

26 Aug 2025
 Chinese Academy of Sciences
Chinese Academy of Sciences University of Science and Technology of China
University of Science and Technology of China Shanghai Jiao Tong University
Shanghai Jiao Tong University Nagoya UniversityInstitut de Robòtica i Informàtica Industrial
Nagoya UniversityInstitut de Robòtica i Informàtica Industrial Aalborg University
Aalborg University EPFL
EPFL University of Tokyo
University of Tokyo Huazhong University of Science and TechnologyUlsan National Institute of Science and TechnologyKeio UniversitySoutheast UniversityBeijing University of Posts and TelecommunicationsKing Abdullah University of Science and TechnologyUniversitat de BarcelonaUniversity of TsukubaUCLouvainMichigan Technological UniversityUniversity of LiègeUniversity of Science and TechnologyKorea Institute of Science and TechnologyUniversity of the Bundeswehr MunichShenzhen Institutes of Advanced TechnologyMax-Planck Institute for InformaticsComputer Vision CenterUniversidad Industrial de SantanderSuzhou Institute for Advanced ResearchState Key Laboratory of Networking and Switching TechnologyLeipzig University of Applied SciencesEscuela Superior Politecnica del LitoralEVS Broadcast EquipmentIntellindust AI LabOpus AI ResearchSportradarTAHAKOMEidos.aiKIST Schoolint8.ioMIXI Inc.Intelligent Perception and Image Understanding LabPlaybox Inc.Laboratory for Biosignal Processing
Huazhong University of Science and TechnologyUlsan National Institute of Science and TechnologyKeio UniversitySoutheast UniversityBeijing University of Posts and TelecommunicationsKing Abdullah University of Science and TechnologyUniversitat de BarcelonaUniversity of TsukubaUCLouvainMichigan Technological UniversityUniversity of LiègeUniversity of Science and TechnologyKorea Institute of Science and TechnologyUniversity of the Bundeswehr MunichShenzhen Institutes of Advanced TechnologyMax-Planck Institute for InformaticsComputer Vision CenterUniversidad Industrial de SantanderSuzhou Institute for Advanced ResearchState Key Laboratory of Networking and Switching TechnologyLeipzig University of Applied SciencesEscuela Superior Politecnica del LitoralEVS Broadcast EquipmentIntellindust AI LabOpus AI ResearchSportradarTAHAKOMEidos.aiKIST Schoolint8.ioMIXI Inc.Intelligent Perception and Image Understanding LabPlaybox Inc.Laboratory for Biosignal Processing
The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at this https URL, with baselines and development kits available at this https URL.

23 Dec 2024

Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.

15 Oct 2025
Integrated photonic circuits are foundational for versatile applications, where high-performance traveling-wave optical resonators are critical. Conventional whispering-gallery mode microresonators (WGMRs) confine light in closed-loop waveguide paths, thus inevitably occupy large footprints. Here, we report an ultracompact high loaded Q silicon photonic WGMR in an open curved path instead. By leveraging spatial mode multiplexing, low-loss mode converter-based photonic routers enable reentrant photon recycling in a single non-closed waveguide. The fabricated device achieves a measured loaded Q-factor of 1.78*10^5 at 1554.3 nm with a 1.05 nm free spectral range in a ultracompact footprint of 0.00137 mm^2-6*smaller than standard WGMRs while delivering 100*higher Q-factor than photonic crystal counterparts. This work pioneers dense integration of high-performance WGMR arrays through open-path mode recirculation.

07 Aug 2025
Generative artificial intelligence (AI) is rapidly transforming medical imaging by enabling capabilities such as data synthesis, image enhancement, modality translation, and spatiotemporal modeling. This review presents a comprehensive and forward-looking synthesis of recent advances in generative modeling including generative adversarial networks (GANs), variational autoencoders (VAEs), diffusion models, and emerging multimodal foundation architectures and evaluates their expanding roles across the clinical imaging continuum. We systematically examine how generative AI contributes to key stages of the imaging workflow, from acquisition and reconstruction to cross-modality synthesis, diagnostic support, and treatment planning. Emphasis is placed on both retrospective and prospective clinical scenarios, where generative models help address longstanding challenges such as data scarcity, standardization, and integration across modalities. To promote rigorous benchmarking and translational readiness, we propose a three-tiered evaluation framework encompassing pixel-level fidelity, feature-level realism, and task-level clinical relevance. We also identify critical obstacles to real-world deployment, including generalization under domain shift, hallucination risk, data privacy concerns, and regulatory hurdles. Finally, we explore the convergence of generative AI with large-scale foundation models, highlighting how this synergy may enable the next generation of scalable, reliable, and clinically integrated imaging systems. By charting technical progress and translational pathways, this review aims to guide future research and foster interdisciplinary collaboration at the intersection of AI, medicine, and biomedical engineering.

08 Sep 2025


ToxicSQL introduces a framework for investigating and exploiting SQL injection vulnerabilities in LLM-based Text-to-SQL models through backdoor attacks. The work demonstrates that these models can be trained with low poisoning rates to generate malicious, executable SQL queries while retaining normal performance on benign inputs, thereby exposing critical security flaws in database interaction systems.

27 Jul 2023

Huawei Cloud Co., Ltd. researchers developed PanGu-Coder2, a Code LLM fine-tuned with the RRTF framework, achieving 61.64% pass@1 on HumanEval and outperforming prior open-source models as well as several larger commercial models.

10 Mar 2025
Magnetic resonance imaging (MRI) reconstruction is a fundamental task aimed
at recovering high-quality images from undersampled or low-quality MRI data.
This process enhances diagnostic accuracy and optimizes clinical applications.
In recent years, deep learning-based MRI reconstruction has made significant
progress. Advancements include single-modality feature extraction using
different network architectures, the integration of multimodal information, and
the adoption of unsupervised or semi-supervised learning strategies. However,
despite extensive research, MRI reconstruction remains a challenging problem
that has yet to be fully resolved. This survey provides a systematic review of
MRI reconstruction methods, covering key aspects such as data acquisition and
preprocessing, publicly available datasets, single and multi-modal
reconstruction models, training strategies, and evaluation metrics based on
image reconstruction and downstream tasks. Additionally, we analyze the major
challenges in this field and explore potential future directions.
There are no more papers matching your filters at the moment.
