
15 Oct 2025
Training large language models (LLMs) from scratch requires significant computational resources, driving interest in developing smaller, domain-specific LLMs that maintain both efficiency and strong task performance. Medium-sized models such as LLaMA, llama} have served as starting points for domain-specific adaptation, but they often suffer from accuracy degradation when tested on specialized datasets. We introduce FineScope, a framework for deriving compact, domain-optimized LLMs from larger pretrained models. FineScope leverages the Sparse Autoencoder (SAE) framework, inspired by its ability to produce interpretable feature representations, to extract domain-specific subsets from large datasets. We apply structured pruning with domain-specific constraints, ensuring that the resulting pruned models retain essential knowledge for the target domain. To further enhance performance, these pruned models undergo self-data distillation, leveraging SAE-curated datasets to restore key domain-specific information lost during pruning. Extensive experiments and ablation studies demonstrate that FineScope achieves highly competitive performance, outperforming several large-scale state-of-the-art LLMs in domain-specific tasks. Additionally, our results show that FineScope enables pruned models to regain a substantial portion of their original performance when fine-tuned with SAE-curated datasets. Furthermore, applying these datasets to fine-tune pretrained LLMs without pruning also improves their domain-specific accuracy, highlighting the robustness of our approach.

20 Feb 2025



Self-supervised monocular depth estimation (SSMDE) aims to predict the dense
depth map of a monocular image, by learning depth from RGB image sequences,
eliminating the need for ground-truth depth labels. Although this approach
simplifies data acquisition compared to supervised methods, it struggles with
reflective surfaces, as they violate the assumptions of Lambertian reflectance,
leading to inaccurate training on such surfaces. To tackle this problem, we
propose a novel training strategy for an SSMDE by leveraging triplet mining to
pinpoint reflective regions at the pixel level, guided by the camera geometry
between different viewpoints. The proposed reflection-aware triplet mining loss
specifically penalizes the inappropriate photometric error minimization on the
localized reflective regions while preserving depth accuracy in non-reflective
areas. We also incorporate a reflection-aware knowledge distillation method
that enables a student model to selectively learn the pixel-level knowledge
from reflective and non-reflective regions. This results in robust depth
estimation across areas. Evaluation results on multiple datasets demonstrate
that our method effectively enhances depth quality on reflective surfaces and
outperforms state-of-the-art SSMDE baselines.

28 Sep 2025
Twisted bilayer MoTe near two-degree twists has emerged as a platform for exotic correlated topological phases, including ferromagnetism and a non-Abelian fractional spin Hall insulator. Here we reveal the unexpected emergence of an intervalley superconducting phase that intervenes between these two states in the half-filled second moiré bands. Using a continuum model and exact diagonalization, we identify superconductivity through multiple signatures: negative binding energy, a dominant pair-density eigenvalue, finite superfluid stiffness, and pairing symmetry consistent with a time-reversal-symmetric nodal extended -wave state. Remarkably, our numerical calculation suggests a continuous transition between superconductivity and the non-Abelian fractional spin Hall insulator, in which topology and symmetry evolve simultaneously, supported by an effective field-theory description. Our results establish higher moiré bands as fertile ground for intertwined superconductivity and topological order, and point to experimentally accessible routes for realizing superconductivity in twisted bilayer MoTe.

13 Sep 2025
Trilayer graphene allows systematic control of its electronic structure through stacking sequence and twist geometry, providing a versatile platform for correlated states. Here we report magnetotransport in alternating twisted trilayer graphene with a twist angle of about 5. The data reveal an electron-hole asymmetry that can be captured by introducing layer-dependent potential shifts. At charge neutrality (), three low-resistance states appear, which Hartree-Fock mean-field analysis attributes to emerging spin-resolved helical edge modes similar to those of quantum spin Hall insulators. At , we also observe suppressed resistance when the middle and bottom layers are each half filled while the top layer remains inert at , consistent with an interlayer excitonic quantum Hall state. These results demonstrate correlated interlayer quantum Hall phases in alternating twisted trilayer graphene, including spin-resolved edge transport and excitonic order.

21 Nov 2023

We present a novel flipping transfer method for van der Waals heterostructures, offering a significant advancement over previous techniques by eliminating the need for polymers and solvents. Here, we utilize commercially available gel film and control its stickiness through oxygen plasma and UV-Ozone treatment, also effectively removing residues from the gel film surface. The cleanliness of the surface is verified through atomic force microscopy. We investigate the quality of our fabricated devices using magnetotransport measurements on graphene/hBN and graphene/{\alpha}-RuCl3 heterostructures. Remarkably,graphene/hBN devices produced with the flipping method display quality similar to that of fully encapsulated devices. This is evidenced by the presence of a symmetry-broken state at 1 T. Additionally, features of the Hofstadter butterfly were also observed in the second devices. In the case of graphene/{\alpha}-RuCl3, we observe quantum oscillations with a beating mode and two-channel conduction, consistent with fully encapsulated devices.

07 Feb 2025
The DGIST-developed SEDI-INSTRUCT framework enhances automated instruction generation for language models by improving data quality and reducing computational costs compared to the Self-Instruct method. It achieved 5.2% higher accuracy on fine-tuned Llama-3-8B models and required 36% fewer API calls to generate an equivalent amount of usable instruction data.

01 Oct 2021



Recently, brain-inspired computing models have shown great potential to outperform today's deep learning solutions in terms of robustness and energy efficiency. Particularly, Spiking Neural Networks (SNNs) and HyperDimensional Computing (HDC) have shown promising results in enabling efficient and robust cognitive learning. Despite the success, these two brain-inspired models have different strengths. While SNN mimics the physical properties of the human brain, HDC models the brain on a more abstract and functional level. Their design philosophies demonstrate complementary patterns that motivate their combination. With the help of the classical psychological model on memory, we propose SpikeHD, the first framework that fundamentally combines Spiking neural network and hyperdimensional computing. SpikeHD generates a scalable and strong cognitive learning system that better mimics brain functionality. SpikeHD exploits spiking neural networks to extract low-level features by preserving the spatial and temporal correlation of raw event-based spike data. Then, it utilizes HDC to operate over SNN output by mapping the signal into high-dimensional space, learning the abstract information, and classifying the data. Our extensive evaluation on a set of benchmark classification problems shows that SpikeHD provides the following benefit compared to SNN architecture: (1) significantly enhance learning capability by exploiting two-stage information processing, (2) enables substantial robustness to noise and failure, and (3) reduces the network size and required parameters to learn complex information.

04 Jun 2020
Recent advances in blockchain have led to a significant interest in developing blockchain-based applications. While data can be retained in blockchains, the stored values can be deleted or updated. From a user viewpoint that searches for the data, it is unclear whether the discovered data from the blockchain storage is relevant for real-time decision-making process for blockchain-based application. The data freshness issue serves as a critical factor especially in dynamic networks handling real-time information. In general, transactions to renew the data require additional processing time inside the blockchain network, which is called ledger-commitment latency. Due to this problem, some users may receive outdated data. As a result, it is important to investigate if blockchain is suitable for providing real-time data services. In this article, we first describe blockchain-enabled (BCE) networks with Hyperledger Fabric (HLF). Then, we define age of information (AoI) of BCE networks and investigate the influential factors in this AoI. Analysis and experiments are conducted to support our proposed framework. Lastly, we conclude by discussing some future challenges.

21 Nov 2023
We present a novel flipping transfer method for van der Waals heterostructures, offering a significant advancement over previous techniques by eliminating the need for polymers and solvents. Here, we utilize commercially available gel film and control its stickiness through oxygen plasma and UV-Ozone treatment, also effectively removing residues from the gel film surface. The cleanliness of the surface is verified through atomic force microscopy. We investigate the quality of our fabricated devices using magnetotransport measurements on graphene/hBN and graphene/{\alpha}-RuCl3 heterostructures. Remarkably,graphene/hBN devices produced with the flipping method display quality similar to that of fully encapsulated devices. This is evidenced by the presence of a symmetry-broken state at 1 T. Additionally, features of the Hofstadter butterfly were also observed in the second devices. In the case of graphene/{\alpha}-RuCl3, we observe quantum oscillations with a beating mode and two-channel conduction, consistent with fully encapsulated devices.

01 Aug 2025
Millimeter-wave (mmWave) communications have gained attention as a key technology for high-capacity wireless systems, owing to the wide available bandwidth. However, mmWave signals suffer from their inherent characteristics such as severe path loss, poor scattering, and limited diffraction, which necessitate the use of large antenna arrays and directional beamforming, typically implemented through massive MIMO architectures. Accurate channel estimation is critical in such systems, but its computational complexity increases proportionally with the number of antennas. This may become a significant burden in mmWave systems where channels exhibit rapid fluctuations and require frequent updates. In this paper, we propose a low-complexity channel denoiser based on Bayesian binary hypothesis testing and beamspace sparsity. By modeling each sparse beamspace component as a mixture of signal and noise under a Bernoulli-complex Gaussian prior, we formulate a likelihood ratio test to detect signal-relevant elements. Then, a hard-thresholding rule is applied to suppress noise-dominant components in the noisy channel vector. Despite its extremely low computational complexity, the proposed method achieves channel estimation accuracy that is comparable to that of complex iterative or learning-based approaches. This effectiveness is supported by both theoretical analysis and numerical evaluation, suggesting that the method can be a viable option for mmWave systems with strict resource constraints.

19 Sep 2017
In various scenarios, achieving security between IoT devices is challenging
since the devices may have different dedicated communication standards,
resource constraints as well as various applications. In this article, we first
provide requirements and existing solutions for IoT security. We then introduce
a new reconfigurable security framework based on edge computing, which utilizes
a near-user edge device, i.e., security agent, to simplify key management and
offload the computational costs of security algorithms at IoT devices. This
framework is designed to overcome the challenges including high computation
costs, low flexibility in key management, and low compatibility in deploying
new security algorithms in IoT, especially when adopting advanced cryptographic
primitives. We also provide the design principles of the reconfigurable
security framework, the exemplary security protocols for anonymous
authentication and secure data access control, and the performance analysis in
terms of feasibility and usability. The reconfigurable security framework paves
a new way to strength IoT security by edge computing.
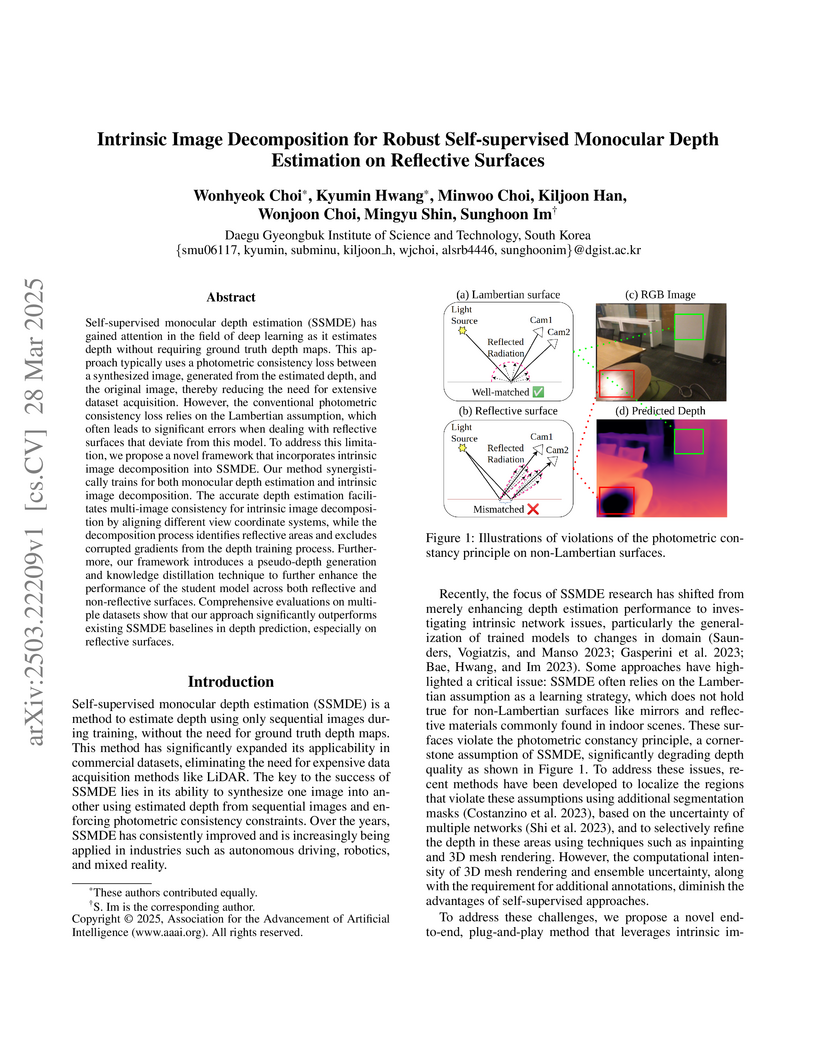
28 Mar 2025
This work from Choi et al. at the Daegu Gyeongbuk Institute of Science and Technology introduces a fully self-supervised framework for monocular depth estimation that robustly handles reflective surfaces by integrating intrinsic image decomposition. The method identifies and excludes problematic reflective regions from depth training, leading to substantial improvements of up to 23.51% on reflective datasets while maintaining performance on non-reflective scenes.

02 Mar 2024

Multi-sensor fusion (MSF) is widely used in autonomous vehicles (AVs) for
perception, particularly for 3D object detection with camera and LiDAR sensors.
The purpose of fusion is to capitalize on the advantages of each modality while
minimizing its weaknesses. Advanced deep neural network (DNN)-based fusion
techniques have demonstrated the exceptional and industry-leading performance.
Due to the redundant information in multiple modalities, MSF is also recognized
as a general defence strategy against adversarial attacks. In this paper, we
attack fusion models from the camera modality that is considered to be of
lesser importance in fusion but is more affordable for attackers. We argue that
the weakest link of fusion models depends on their most vulnerable modality,
and propose an attack framework that targets advanced camera-LiDAR fusion-based
3D object detection models through camera-only adversarial attacks. Our
approach employs a two-stage optimization-based strategy that first thoroughly
evaluates vulnerable image areas under adversarial attacks, and then applies
dedicated attack strategies for different fusion models to generate deployable
patches. The evaluations with six advanced camera-LiDAR fusion models and one
camera-only model indicate that our attacks successfully compromise all of
them. Our approach can either decrease the mean average precision (mAP) of
detection performance from 0.824 to 0.353, or degrade the detection score of a
target object from 0.728 to 0.156, demonstrating the efficacy of our proposed
attack framework. Code is available.

07 Feb 2022

We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 76.24, whereas the second-best method achieves 114.51.

26 Apr 2020
A traffic monitoring system (TMS) is an integral part of Intelligent Transportation Systems (ITS). It is an essential tool for traffic analysis and planning. One of the biggest challenges is, however, the high cost especially in covering the huge rural road network. In this paper, we propose to address the problem by developing a novel TMS called DeepWiTraffic. DeepWiTraffic is a low-cost, portable, and non-intrusive solution that is built only with two WiFi transceivers. It exploits the unique WiFi Channel State Information (CSI) of passing vehicles to perform detection and classification of vehicles. Spatial and temporal correlations of CSI amplitude and phase data are identified and analyzed using a machine learning technique to classify vehicles into five different types: motorcycles, passenger vehicles, SUVs, pickup trucks, and large trucks. A large amount of CSI data and ground-truth video data are collected over a month period from a real-world two-lane rural roadway to validate the effectiveness of DeepWiTraffic. The results validate that DeepWiTraffic is an effective TMS with the average detection accuracy of 99.4% and the average classification accuracy of 91.1% in comparison with state-of-the-art non-intrusive TMSs.

26 Nov 2018
We investigate an entangled system, which is analogous to a composite system
of a black hole and Hawking radiation. If Hawking radiation is well
approximated by an outgoing particle generated from pair creation around the
black hole, such a pair creation increases the total number of states. There
should be a unitary mechanism to reduce the number of states inside the horizon
for black hole evaporation. Because the infalling antiparticle has negative
energy, as long as the infalling antiparticle finds its partner such that the
two particles form a separable state, one can trace out such a zero energy
system by maintaining unitarity. In this paper, based on some toy model
calculations, we show that such a unitary tracing-out process is only possible
before the Page time while it is impossible after the Page time. Hence, after
the Page time, if we assume that the process is unitary and the Hawking pair
forms a separable state, the internal number of states will monotonically
increase, which is supported by the Almheiri-Marolf-Polchinski-Sully (AMPS)
argument. In addition, the Hawking particles cannot generate randomness of the
entire system; hence, the entanglement entropy cannot reach its maximum. Based
on these results, we modify the correct form of the Page curve for the remnant
picture. The most important conclusion is this: if we assume unitarity,
semi-classical quantum field theory, and general relativity, then the black
hole should violate the Bekenstein-Hawking entropy bound around the Page time
at the latest; hence, the infinite production arguments for remnants might be
applied for semi-classical black holes, which seems very problematic.

19 Aug 2020
Brain-Computer Interfaces (BCI) based on Electroencephalography (EEG)
signals, in particular motor imagery (MI) data have received a lot of attention
and show the potential towards the design of key technologies both in
healthcare and other industries. MI data is generated when a subject imagines
movement of limbs and can be used to aid rehabilitation as well as in
autonomous driving scenarios. Thus, classification of MI signals is vital for
EEG-based BCI systems. Recently, MI EEG classification techniques using deep
learning have shown improved performance over conventional techniques. However,
due to inter-subject variability, the scarcity of unseen subject data, and low
signal-to-noise ratio, extracting robust features and improving accuracy is
still challenging. In this context, we propose a novel two-way few shot network
that is able to efficiently learn how to learn representative features of
unseen subject categories and how to classify them with limited MI EEG data.
The pipeline includes an embedding module that learns feature representations
from a set of samples, an attention mechanism for key signal feature discovery,
and a relation module for final classification based on relation scores between
a support set and a query signal. In addition to the unified learning of
feature similarity and a few shot classifier, our method leads to emphasize
informative features in support data relevant to the query data, which
generalizes better on unseen subjects. For evaluation, we used the BCI
competition IV 2b dataset and achieved an 9.3% accuracy improvement in the
20-shot classification task with state-of-the-art performance. Experimental
results demonstrate the effectiveness of employing attention and the overall
generality of our method.

23 Nov 2022
Autonomous vehicle simulation has the advantage of testing algorithms in
various environment variables and scenarios without wasting time and resources,
however, there is a visual gap with the real-world. In this paper, we trained
DCLGAN to realistically convert the image of the CARLA simulator and evaluated
the effect of the Sim2Real conversion focusing on the LKAS (Lane Keeping Assist
System) algorithm. In order to avoid the case where the lane is translated
distortedly by DCLGAN, we found the optimal training hyperparameter using FSIM
(feature-similarity). After training, we built a system that connected the
DCLGAN model with CARLA and AV in real-time. Then, we collected data (e.g.
images, GPS) and analyzed them using the following four methods. First, image
reality was measured with FID, which we verified quantitatively reflects the
lane characteristics. CARLA images that passed through DCLGAN had smaller FID
values than the original images. Second, lane segmentation accuracy through
ENet-SAD was improved by DCLGAN. Third, in the curved route, the case of using
DCLGAN drove closer to the center of the lane and had a high success rate.
Lastly, in the straight route, DCLGAN improved lane restoring ability after
deviating from the center of the lane as much as in reality.

29 May 2024

Recent studies have explored the deployment of privacy-preserving deep neural
networks utilizing homomorphic encryption (HE), especially for private
inference (PI). Many works have attempted the approximation-aware training
(AAT) approach in PI, changing the activation functions of a model to
low-degree polynomials that are easier to compute on HE by allowing model
retraining. However, due to constraints in the training environment, it is
often necessary to consider post-training approximation (PTA), using the
pre-trained parameters of the existing plaintext model without retraining.
Existing PTA studies have uniformly approximated the activation function in all
layers to a high degree to mitigate accuracy loss from approximation, leading
to significant time consumption. This study proposes an optimized layerwise
approximation (OLA), a systematic framework that optimizes both accuracy loss
and time consumption by using different approximation polynomials for each
layer in the PTA scenario. For efficient approximation, we reflect the
layerwise impact on the classification accuracy by considering the actual input
distribution of each activation function while constructing the optimization
problem. Additionally, we provide a dynamic programming technique to solve the
optimization problem and achieve the optimized layerwise degrees in polynomial
time. As a result, the OLA method reduces inference times for the ResNet-20
model and the ResNet-32 model by 3.02 times and 2.82 times, respectively,
compared to prior state-of-the-art implementations employing uniform degree
polynomials. Furthermore, we successfully classified CIFAR-10 by replacing the
GELU function in the ConvNeXt model with only 3-degree polynomials using the
proposed method, without modifying the backbone model.

14 Dec 2023
As advanced V2X applications emerge in the connected and autonomous vehicle (CAV), the data communications between in-vehicle end-devices and outside nodes increase, which make the end-to-end (E2E) security to in-vehicle end-devices as the urgent issue to be handled. However, the E2E security with fine-grained access control still remains as a challenging issue for resource-constrained end-devices since the existing security solutions require complicated key management and high resource consumption. Therefore, we propose a practical and secure vehicular communication protocol for the E2E security based on a new attribute-based encryption (ABE) scheme. In our scheme, the outsourced computation is provided for encryption, and the computation cost for decryption constantly remains small, regardless of the number of attributes. The policy privacy can be ensured by the proposed ABE to support privacy-sensitive V2X applications, and the existing identity-based signature for outsourced signing is newly reconstructed. Our scheme achieves the confidentiality, message authentication, identity anonymity, unlinkability, traceability, and reconfigurable outsourced computation, and we also show the practical feasibility of our protocol via the performance evaluation.
There are no more papers matching your filters at the moment.
