
21 Sep 2025

Non-equilibrium dynamics of unentangled and entangled pure states in interacting quantum systems is crucial for harnessing quantum information and to understand quantum thermalization. We develop a general Schwinger-Keldysh (SK) field theory for non-equilibrium dynamics of pure states of fermions. We apply our formalism to study the time evolution of initial density inhomogeneity and multi-point correlations of pure states in the complex Sachdev-Ye-Kitaev (SYK) models. We demonstrate a remarkable universality in the dynamics of pure states in the SYK model. We show that dynamics of almost all pure states in a fixed particle number sector is solely determined by a set of universal large- Kadanoff-Baym equations. Moreover, irrespective of the initial state the site- and disorder-averaged Green's function thermalizes instantaneously, whereas local and non-local Green's functions have finite thermalization rate. We provide understanding of our numerical and analytical large- results through random-matrix theory (RMT) analysis. Furthermore, we show that the thermalization of an initial pure product state in the non-interacting SYK model is independent of fermion filling and an initial density inhomogeneity decays with weak but long lived oscillations due to dephasing. In contrast, the interacting SYK model thermalizes slower than the non-interacting model and exhibits filling-dependent monotonic relaxation of initial inhomogeneity. For evolution of entangled pure states, we show that the initial entanglement is encoded in the non-local and/or multi-point quantum correlations that relax as the system thermalizes.

05 Sep 2025
Automating scientific research is considered the final frontier of science. Recently, several papers claim autonomous research agents can generate novel research ideas. Amidst the prevailing optimism, we document a critical concern: a considerable fraction of such research documents are smartly plagiarized. Unlike past efforts where experts evaluate the novelty and feasibility of research ideas, we request experts to operate under a different situational logic: to identify similarities between LLM-generated research documents and existing work. Concerningly, the experts identify of the evaluated research documents to be either paraphrased (with one-to-one methodological mapping), or significantly borrowed from existing work. These reported instances are cross-verified by authors of the source papers. The remaining of documents show varying degrees of similarity with existing work, with only a small fraction appearing completely novel. Problematically, these LLM-generated research documents do not acknowledge original sources, and bypass inbuilt plagiarism detectors. Lastly, through controlled experiments we show that automated plagiarism detectors are inadequate at catching plagiarized ideas from such systems. We recommend a careful assessment of LLM-generated research, and discuss the implications of our findings on academic publishing.

02 Sep 2025
The LITHE system, developed by researchers at the Indian Institute of Science and Microsoft Research India, utilizes Large Language Models (LLMs) to transform inefficient SQL queries into semantically equivalent and more performant alternatives. This approach achieved a 13.2x geometric mean speedup in query execution time over native optimizers and generated 26 cost-productive rewrites on TPC-DS, outperforming state-of-the-art rewriters while ensuring correctness.

02 Dec 2025
The lecture notes cover the basics of quantum computing methods for quantum field theory applications. No detailed knowledge of either quantum computing or quantum field theory is assumed and we have attempted to keep the material at a pedagogical level. We review the anharmonic oscillator, using which we develop a hands-on treatment of certain interesting QFTs in : theory, Ising field theory, and the Schwinger model. We review quantum computing essentials as well as tensor network techniques. The latter form an essential part for quantum computing benchmarking. Some error modelling on QISKIT is also done in the hope of anticipating runs on NISQ devices.
These lecture notes are the expanded version of a one semester course taught by AS during August-November 2025 at the Indian Institute of Science and TA-ed by UB. The programs written for this course are available in a GitHub repository.

09 Aug 2025


Global cloud service providers handle inference workloads for Large Language Models (LLMs) that span latency-sensitive (e.g., chatbots) and insensitive (e.g., report writing) tasks, resulting in diverse and often conflicting Service Level Agreement (SLA) requirements. Managing such mixed workloads is challenging due to the complexity of the inference serving stack, which encompasses multiple models, GPU hardware, and global data centers. Existing solutions often silo such fast and slow tasks onto separate GPU resource pools with different SLAs, but this leads to significant under-utilization of expensive accelerators due to load mismatch. In this article, we characterize the LLM serving workloads at Microsoft Office 365, one of the largest users of LLMs within Microsoft Azure cloud with over 10 million requests per day, and highlight key observations across workloads in different data center regions and across time. This is one of the first such public studies of Internet-scale LLM workloads. We use these insights to propose SageServe, a comprehensive LLM serving framework that dynamically adapts to workload demands using multi-timescale control knobs. It combines short-term request routing to data centers with long-term scaling of GPU VMs and model placement with higher lead times, and co-optimizes the routing and resource allocation problem using a traffic forecast model and an Integer Linear Programming (ILP) solution. We evaluate SageServe through real runs and realistic simulations on 10 million production requests across three regions and four open-source models. We achieve up to 25% savings in GPU-hours compared to the current baseline deployment and reduce GPU-hour wastage due to inefficient auto-scaling by 80%, resulting in a potential monthly cost savings of up to $2.5 million, while maintaining tail latency and meeting SLAs.

10 Oct 2025

Large Language Models (LLMs) have demonstrated strong performance across general NLP tasks, but their utility in automating numerical experiments of complex physical system -- a critical and labor-intensive component -- remains underexplored. As the major workhorse of computational science over the past decades, Computational Fluid Dynamics (CFD) offers a uniquely challenging testbed for evaluating the scientific capabilities of LLMs. We introduce CFDLLMBench, a benchmark suite comprising three complementary components -- CFDQuery, CFDCodeBench, and FoamBench -- designed to holistically evaluate LLM performance across three key competencies: graduate-level CFD knowledge, numerical and physical reasoning of CFD, and context-dependent implementation of CFD workflows. Grounded in real-world CFD practices, our benchmark combines a detailed task taxonomy with a rigorous evaluation framework to deliver reproducible results and quantify LLM performance across code executability, solution accuracy, and numerical convergence behavior. CFDLLMBench establishes a solid foundation for the development and evaluation of LLM-driven automation of numerical experiments for complex physical systems. Code and data are available at this https URL.

29 Jan 2025
vAttention introduces a dynamic memory management system for serving Large Language Models that eliminates KV cache fragmentation while maintaining virtual memory contiguity. This approach, leveraging CUDA virtual memory management (VMM) APIs, achieves up to 1.36x higher prefill throughput, up to 42% lower online inference latency, and enables out-of-the-box support for new, optimized attention kernels like FlashAttention-3.

28 Apr 2025
Researchers from IISc and CMU establish fundamental lower bounds on sample complexity for sequential hypothesis testing, proving that the expected number of samples scales with O(log(1/alpha)) where alpha is the type I error probability, while providing matching upper bounds and sufficient conditions for achieving optimality across parametric and non-parametric settings.

11 Oct 2025

The paper introduces Reliable Policy Iteration (RPI) and Conservative Reliable Policy Iteration (CRPI), algorithms extending classical policy iteration to function approximation by restoring theoretical guarantees for monotonic value estimates and per-step policy improvement. These methods demonstrate enhanced learning stability and achieve higher-quality policies across various reward environments compared to existing approximate policy iteration approaches.

03 Dec 2025
Researchers from the Indian Institute of Science, Bengaluru, introduce SelfDebias, a fully unsupervised, test-time framework designed to mitigate biases in text-to-image diffusion models without requiring human supervision or model retraining. The framework demonstrates superior fairness performance on demographic and occupation-related biases, and uniquely debiases abstract concepts by automatically discovering semantic modes.

19 Jun 2025

Code translation transforms programs from one programming language (PL) to another. Several rule-based transpilers have been designed to automate code translation between different pairs of PLs. However, the rules can become obsolete as the PLs evolve and cannot generalize to other PLs. Recent studies have explored the automation of code translation using Large Language Models (LLMs). One key observation is that such techniques may work well for crafted benchmarks but fail to generalize to the scale and complexity of real-world projects with dependencies, custom types, PL-specific features, etc. We propose AlphaTrans, a neuro-symbolic approach to automate repository-level code translation. AlphaTrans translates both source and test code, and employs multiple levels of validation to ensure the translation preserves the functionality of the source program. To break down the problem for LLMs, AlphaTrans leverages program analysis to decompose the program into fragments and translates them in the reverse call order. We leveraged AlphaTrans to translate ten real-world open-source projects consisting of <836, 8575, 2719> classes, methods, and tests. AlphaTrans breaks down these projects into 17874 fragments and translates the entire repository. 96.40% of the translated fragments are syntactically correct, and AlphaTrans validates the translations' runtime behavior and functional correctness for 27.03% and 25.14% of fragments. On average, the integrated translation and validation take 34 hours to translate a project, showing its scalability in practice. For the incorrect translations, AlphaTrans generates a report including existing translation, stack trace, test errors, or assertion failures. We provided these artifacts to two developers to fix the translation bugs in four projects. They were able to fix the issues in 20.1 hours on average and achieve all passing tests.

15 Nov 2025
This paper critically examines the prevailing "world model" framework in AI, arguing that it is insufficient for characterizing human-level understanding despite its advancements in simulation and prediction. Through philosophical case studies, it reveals that human understanding involves a deeper grasp of abstract concepts, contextual motivations, and explanatory purposes that current world models do not inherently capture.

22 Sep 2025
3D Gaussian Splatting (3DGS) has shown impressive results in real-time novel view synthesis. However, it often struggles under sparse-view settings, producing undesirable artifacts such as floaters, inaccurate geometry, and overfitting due to limited observations. We find that a key contributing factor is uncontrolled densification, where adding Gaussian primitives rapidly without guidance can harm geometry and cause artifacts. We propose AD-GS, a novel alternating densification framework that interleaves high and low densification phases. During high densification, the model densifies aggressively, followed by photometric loss based training to capture fine-grained scene details. Low densification then primarily involves aggressive opacity pruning of Gaussians followed by regularizing their geometry through pseudo-view consistency and edge-aware depth smoothness. This alternating approach helps reduce overfitting by carefully controlling model capacity growth while progressively refining the scene representation. Extensive experiments on challenging datasets demonstrate that AD-GS significantly improves rendering quality and geometric consistency compared to existing methods. The source code for our model can be found on our project page: this https URL .

10 May 2024
 University of Washington
University of Washington CNRS
CNRS Monash University
Monash University Carnegie Mellon UniversityAllen Institute for Artificial Intelligence
Carnegie Mellon UniversityAllen Institute for Artificial Intelligence Georgia Institute of TechnologyIT University of Copenhagen
Georgia Institute of TechnologyIT University of Copenhagen University of British ColumbiaIndian Institute of Science
University of British ColumbiaIndian Institute of Science Université Paris-Saclay
Université Paris-Saclay Mohamed bin Zayed University of Artificial IntelligenceIndian Institute of Technology
Mohamed bin Zayed University of Artificial IntelligenceIndian Institute of Technology University of SydneyThe Hebrew University of JerusalemTechnical University of DarmstadtUniversität HamburgBocconi UniversityRadboud University NijmegenLISNUniversity of Applied Sciences DarmstadtQueens
’ University
University of SydneyThe Hebrew University of JerusalemTechnical University of DarmstadtUniversität HamburgBocconi UniversityRadboud University NijmegenLISNUniversity of Applied Sciences DarmstadtQueens
’ UniversityA white paper resulting from a Dagstuhl seminar systematically maps the scientific peer review process, identifying specific challenges and opportunities for Natural Language Processing (NLP) solutions across all stages. It outlines how NLP can assist from submission preparation to post-review analysis, while also highlighting critical overarching challenges related to data, measurement, and ethics.

18 Nov 2025
While Large Vision Language Models (LVLMs) are increasingly deployed in real-world applications, their ability to interpret abstract visual inputs remains limited. Specifically, they struggle to comprehend hand-drawn sketches, a modality that offers an intuitive means of expressing concepts that are difficult to describe textually. We identify the primary bottleneck as the absence of a large-scale dataset that jointly models sketches, photorealistic images, and corresponding natural language instructions. To address this, we present two key contributions: (1) a new, large-scale dataset of image-sketch-instruction triplets designed to facilitate both pretraining and instruction tuning, and (2) O3SLM, an LVLM trained on this dataset. Comprehensive evaluations on multiple sketch-based tasks: (a) object localization, (b) counting, (c) image retrieval i.e., (SBIR and fine-grained SBIR), and (d) visual question answering (VQA); while incorporating the three existing sketch datasets, namely QuickDraw!, Sketchy, and Tu Berlin, along with our generated SketchVCL dataset, show that O3SLM achieves state-of-the-art performance, substantially outperforming existing LVLMs in sketch comprehension and reasoning.

19 May 2020
Reinforcement learning (RL) methods learn optimal decisions in the presence of a stationary environment. However, the stationary assumption on the environment is very restrictive. In many real world problems like traffic signal control, robotic applications, one often encounters situations with non-stationary environments and in these scenarios, RL methods yield sub-optimal decisions. In this paper, we thus consider the problem of developing RL methods that obtain optimal decisions in a non-stationary environment. The goal of this problem is to maximize the long-term discounted reward achieved when the underlying model of the environment changes over time. To achieve this, we first adapt a change point algorithm to detect change in the statistics of the environment and then develop an RL algorithm that maximizes the long-run reward accrued. We illustrate that our change point method detects change in the model of the environment effectively and thus facilitates the RL algorithm in maximizing the long-run reward. We further validate the effectiveness of the proposed solution on non-stationary random Markov decision processes, a sensor energy management problem and a traffic signal control problem.
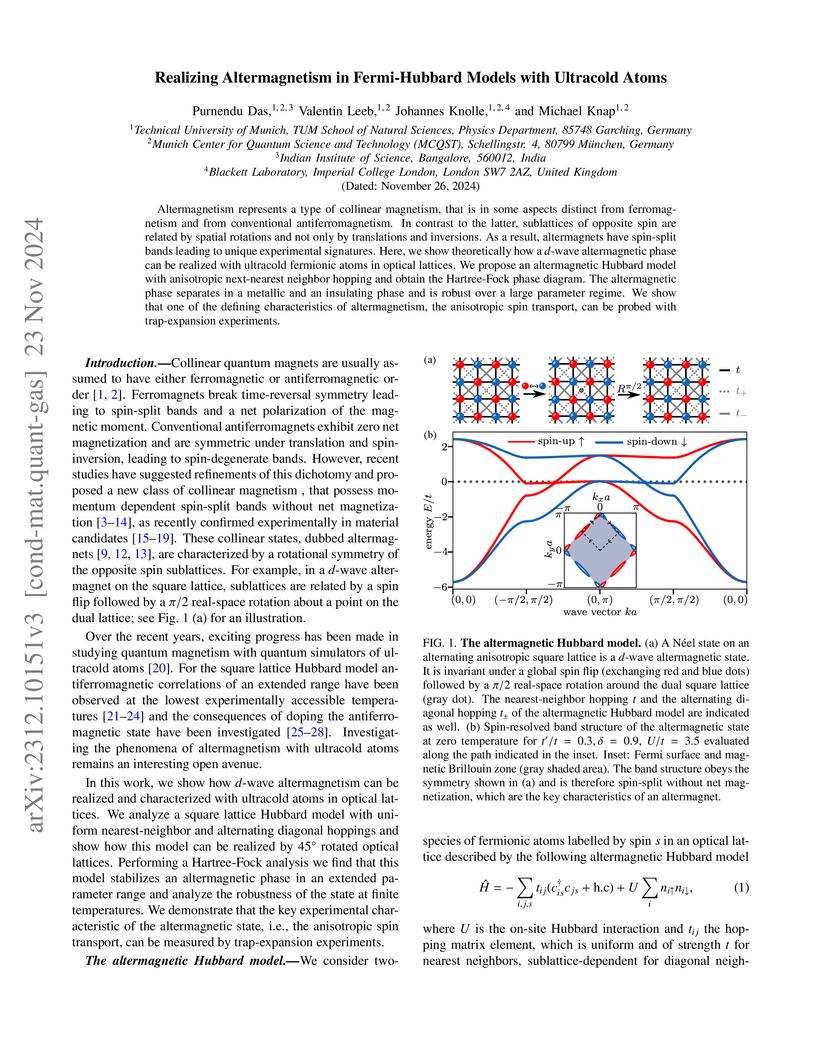
23 Nov 2024


Altermagnetism represents a type of collinear magnetism, that is in some aspects distinct from ferromagnetism and from conventional antiferromagnetism. In contrast to the latter, sublattices of opposite spin are related by spatial rotations and not only by translations and inversions. As a result, altermagnets have spin-split bands leading to unique experimental signatures. Here, we show theoretically how a d-wave altermagnetic phase can be realized with ultracold fermionic atoms in optical lattices. We propose an altermagnetic Hubbard model with anisotropic next-nearest neighbor hopping and obtain the Hartree-Fock phase diagram. The altermagnetic phase separates in a metallic and an insulating phase and is robust over a large parameter regime. We show that one of the defining characteristics of altermagnetism, the anisotropic spin transport, can be probed with trap-expansion experiments.

03 Aug 2024
This study aims to learn a translation from visible to infrared imagery, bridging the domain gap between the two modalities so as to improve accuracy on downstream tasks including object detection. Previous approaches attempt to perform bi-domain feature fusion through iterative optimization or end-to-end deep convolutional networks. However, we pose the problem as similar to that of image translation, adopting a two-stage training strategy with a Generative Adversarial Network and an object detection model. The translation model learns a conversion that preserves the structural detail of visible images while preserving the texture and other characteristics of infrared images. Images so generated are used to train standard object detection frameworks including Yolov5, Mask and Faster RCNN. We also investigate the usefulness of integrating a super-resolution step into our pipeline to further improve model accuracy, and achieve an improvement of as high as 5.3% mAP.

16 Sep 2025
Magnetotransport measurements are a sensitive probe of symmetry and electronic structure in quantum materials. While conventional metals exhibit longitudinal magnetoconductivity that is even in a magnetic field () for small , we show that magnetic materials which intrinsically break time-reversal symmetry (TRS) show an {\it odd-parity magnetoconductivity} (OMC), with a leading linear- response. Using semiclassical transport theory, we derive explicit expressions for the longitudinal and transverse conductivities and identify their origin in Berry curvature and orbital magnetic moment. Crystalline symmetry analysis shows that longitudinal OMC follows the same point-group constraints as the anomalous Hall effect, while transverse OMC obeys distinct rules, providing an independent probe of TRS breaking. In the large quantum oscillation regime, we uncover both odd- and even- contributions, demonstrating OMC beyond the semiclassical picture. Explicit calculations in valley-polarized gapped graphene show that OMC peaks near the band edges, vanish in the band gap and follow the temperature dependence of the magnetic order parameter. Our results explain the odd-parity magnetoresistance recently observed in magnetized graphene and establish OMC as a robust transport signature of intrinsic TRS breaking in metals.

12 Sep 2025
Quantum key distribution (QKD) using entangled photon sources (EPS) is a cornerstone of secure communication. Despite rapid advances in QKD, conventional protocols still employ beam splitters (BSs) for passive random basis selection. However, BSs intrinsically suffer from photon loss, imperfect splitting ratios, and polarization dependence, limiting the key rate, increasing the quantum bit error rate (QBER), and constraining scalability, particularly over long distances. By contrast, EPSs based on spontaneous parametric down-conversion (SPDC) intrinsically exhibit quantum randomness in spatial and spectral degrees of freedom, offering a natural replacement for BSs in basis selection. Here, we demonstrate a proof-of-concept spatial-randomness-based QKD scheme in which the annular SPDC emission ring is divided into four sections, effectively generating two independent EPSs. pair photons from these sources, distributed to Alice and Bob, enable H/V and D/A measurements. The quantum-random pair generation inherently mimics the stochastic basis choice otherwise performed by a BS. Experimentally, our scheme achieves a 6.4-fold enhancement in sifted key rate, a consistently reduced QBER, and a near-ideal encoding balance between logical bits 0 and 1. Furthermore, the need for four spatial channels can be avoided by employing wavelength demultiplexing to generate two EPSs at distinct wavelength pairs. Harnessing intrinsic spatial/spectral randomness thus enables robust, bias-free, high-rate, and low-QBER QKD, offering a scalable pathway for next-generation quantum networks.
There are no more papers matching your filters at the moment.
