
19 Nov 2024
Researchers from Indiana University and eBay conducted the first comprehensive comparative survey of Learning to Rank algorithms in e-commerce, experimentally validating various methods on a proprietary dataset. Their analysis showed that listwise approaches, especially ListMLE, perform best, and spherical text embeddings consistently surpass eBERT for capturing query-product relevance.

06 Aug 2024



Materials hosting flat electronic bands are a central focus of condensed matter physics as promising venues for novel electronic ground states. Two-dimensional (2D) geometrically frustrated lattices such as the kagome, dice, and Lieb lattices are attractive targets in this direction, anticipated to realize perfectly flat bands. Synthesizing these special structures, however, poses a formidable challenge, exemplified by the absence of solid-state materials realizing the dice and Lieb lattices. An alternative route leverages atomic orbitals to create the characteristic electron hopping of geometrically frustrated lattices. This strategy promises to expand the list of candidate materials to simpler structures, but is yet to be demonstrated experimentally. Here, we report the realization of frustrated hopping in the van der Waals (vdW) intermetallic PdAlI, emerging from orbital decoration of a primitive square lattice. Using angle-resolved photoemission spectroscopy and quantum oscillations measurements, we demonstrate that the band structure of PdAlI includes linear Dirac-like bands intersected at their crossing point by a flat band, essential characteristics of frustrated hopping in the Lieb and dice lattices. Moreover, PdAlI is exceptionally stable, with the unusual bulk band structure and metallicity persisting in ambient conditions down to the monolayer limit. Our ability to realize an electronic structure characteristic of geometrically frustrated lattices establishes orbital decoration of primitive lattices as a new approach towards electronic structures that remain elusive to prevailing lattice-centric searches.

11 Mar 2022
Facebook Carnegie Mellon University
Carnegie Mellon University UC Berkeley
UC Berkeley National University of SingaporeIndiana University
National University of SingaporeIndiana University University of Bristol
University of Bristol University of Texas at Austin
University of Texas at Austin University of Pennsylvania
University of Pennsylvania University of Minnesota
University of Minnesota University of TokyoGeorgia Tech
University of TokyoGeorgia Tech MITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality Labs
MITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality Labs
Carnegie Mellon UniversityUC BerkeleyNational University of SingaporeIndiana UniversityUniversity of BristolUniversity of Texas at AustinUniversity of PennsylvaniaUniversity of MinnesotaUniversity of TokyoGeorgia TechMITKing Abdullah University of Science and TechnologyUniversity of CataniaInternational Institute of Information Technology, HyderabadUniversidad de Los AndesCarnegie Mellon University AfricaDartmouthFacebook AI ResearchFacebook Reality LabsEgo4D introduces a large-scale collection of 3,670 hours of egocentric video, captured globally from 931 unique wearers, complemented by modalities like audio, 3D environment meshes, and eye gaze. This dataset and its five associated benchmarks aim to advance research in first-person visual perception for embodied AI, enabling tasks such as episodic memory, hand-object manipulation, and activity forecasting.

25 Sep 2024
Carnegie Mellon UniversityUC BerkeleyNational University of SingaporeIndiana UniversityUniversity of Bristol MetaUniversity of Texas at AustinUniversity of Pennsylvania
MetaUniversity of Texas at AustinUniversity of Pennsylvania Johns Hopkins UniversityUniversity of MinnesotaUniversity of TokyoGeorgia TechKing Abdullah University of Science and TechnologyUniversity of CataniaSimon Fraser UniversityUniversity of North Carolina, Chapel HillInternational Institute of Information Technology, HyderabadUniversidad de Los AndesFAIR, MetaUniversity of Illinois Urbana
ChampaignProject Aria, Meta
Johns Hopkins UniversityUniversity of MinnesotaUniversity of TokyoGeorgia TechKing Abdullah University of Science and TechnologyUniversity of CataniaSimon Fraser UniversityUniversity of North Carolina, Chapel HillInternational Institute of Information Technology, HyderabadUniversidad de Los AndesFAIR, MetaUniversity of Illinois Urbana
ChampaignProject Aria, Meta

Ego-Exo4D introduces the largest public dataset of time-synchronized, multimodal, multiview ego-exocentric video, capturing 740 participants performing skilled activities across 8 diverse domains in 123 natural environments. The dataset, a collaboration of 15 institutions, includes Project Aria data and extensive language annotations, supporting four benchmark families for understanding human skill.

15 Jul 2025

SocioVerse introduces a robust framework for large-scale social simulations, effectively aligning LLM-powered agents and their environments with real-world user behaviors by leveraging a pool of 10 million real-world users. The system achieves high accuracy in predicting outcomes for diverse scenarios, including presidential elections, news feedback, and economic surveys, demonstrating strong fidelity to actual social dynamics.

08 Dec 2024
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign Imperial College London
Imperial College London University of ManchesterNational University of Singapore
University of ManchesterNational University of Singapore Georgia Institute of TechnologyIndiana University
Georgia Institute of TechnologyIndiana University Kyoto University
Kyoto University Zhejiang UniversityUniversity of EdinburghAarhus UniversityThe University of Texas at DallasNational Taiwan Normal UniversityAppCubic
Zhejiang UniversityUniversity of EdinburghAarhus UniversityThe University of Texas at DallasNational Taiwan Normal UniversityAppCubic University of Wisconsin-Madison
University of Wisconsin-Madison Rutgers University
Rutgers University Purdue University
Purdue University HKUSTNational Tsing-Hua UniversityUniversity of Hawai’iXi'an Jiaotong Liverpool UniversitySchool of Visual ArtsPingtan Research Institute of Xiamen UniversityJTB Technology Corp.
HKUSTNational Tsing-Hua UniversityUniversity of Hawai’iXi'an Jiaotong Liverpool UniversitySchool of Visual ArtsPingtan Research Institute of Xiamen UniversityJTB Technology Corp.

A comprehensive guide created by a large inter-institutional collaboration synthesizes the field of Explainable AI (XAI), from classical models to Large Language Models (LLMs). It details diverse XAI techniques and their practical implementation, providing clear definitions, evaluations, and future directions for transparent and trustworthy AI.

06 Jun 2025






Researchers from multiple institutions present a comprehensive survey of methods for enhancing the efficiency of diffusion models, addressing their high computational costs and slow generation times. The work establishes a detailed taxonomy categorizing efficiency techniques across algorithmic, system-level, and framework perspectives, providing a structured understanding of advancements in this area.

20 Mar 2025

A comprehensive framework introduces LLM-based Agentic Recommender Systems (LLM-ARS), combining multimodal large language models with autonomous capabilities to enable proactive, adaptive recommendation experiences while identifying core challenges in safety, efficiency, and personalization across recommendation domains.

27 Sep 2025





A collaborative research effort provides a comprehensive review and benchmark of discrete audio tokenizers, proposing a new multi-dimensional taxonomy and conducting controlled ablation studies across speech, music, and general audio domains. It evaluates tokenizers on reconstruction quality, downstream task performance, and acoustic language modeling, offering a unified framework for understanding their varied trade-offs and optimal applications.

19 Aug 2025
We introduce ResPlan, a large-scale dataset of 17,000 detailed, structurally rich, and realistic residential floor plans, created to advance spatial AI research. Each plan includes precise annotations of architectural elements (walls, doors, windows, balconies) and functional spaces (such as kitchens, bedrooms, and bathrooms). ResPlan addresses key limitations of existing datasets such as RPLAN (Wu et al., 2019) and MSD (van Engelenburg et al., 2024) by offering enhanced visual fidelity and greater structural diversity, reflecting realistic and non-idealized residential layouts. Designed as a versatile, general-purpose resource, ResPlan supports a wide range of applications including robotics, reinforcement learning, generative AI, virtual and augmented reality, simulations, and game development. Plans are provided in both geometric and graph-based formats, enabling direct integration into simulation engines and fast 3D conversion. A key contribution is an open-source pipeline for geometry cleaning, alignment, and annotation refinement. Additionally, ResPlan includes structured representations of room connectivity, supporting graph-based spatial reasoning tasks. Finally, we present comparative analyses with existing benchmarks and outline several open benchmark tasks enabled by ResPlan. Ultimately, ResPlan offers a significant advance in scale, realism, and usability, providing a robust foundation for developing and benchmarking next-generation spatial intelligence systems.

21 May 2025
 University of CambridgeHeidelberg University
University of CambridgeHeidelberg University University of Waterloo
University of Waterloo UCLA
UCLA New York University
New York University University College London
University College London University of OxfordGeorgia Institute of TechnologyIndiana University
University of OxfordGeorgia Institute of TechnologyIndiana University Stanford University
Stanford University ETH Zürich
ETH Zürich University of California, San Diego
University of California, San Diego Northwestern UniversityUniversidade de LisboaAarhus University
Northwestern UniversityUniversidade de LisboaAarhus University EPFLPurdue UniversityFriedrich-Alexander-Universität Erlangen-NürnbergUniversity of ArkansasMIT
EPFLPurdue UniversityFriedrich-Alexander-Universität Erlangen-NürnbergUniversity of ArkansasMIT Princeton UniversityUniversity of Tübingen
Princeton UniversityUniversity of Tübingen University of WarwickHumboldt-Universität zu BerlinLondon School of Economics and Political ScienceUniversity of JohannesburgUniversity of Leeds
University of WarwickHumboldt-Universität zu BerlinLondon School of Economics and Political ScienceUniversity of JohannesburgUniversity of Leeds University of BaselAutonomous University of BarcelonaFederal Reserve Bank of ChicagoUmea UniversityUnversity of MarylandEquiano InstituteModulo ResearchUniversity of Guelph-Humber
University of BaselAutonomous University of BarcelonaFederal Reserve Bank of ChicagoUmea UniversityUnversity of MarylandEquiano InstituteModulo ResearchUniversity of Guelph-HumberWe directly compare the persuasion capabilities of a frontier large language
model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an
interactive, real-time conversational quiz setting. In this preregistered,
large-scale incentivized experiment, participants (quiz takers) completed an
online quiz where persuaders (either humans or LLMs) attempted to persuade quiz
takers toward correct or incorrect answers. We find that LLM persuaders
achieved significantly higher compliance with their directional persuasion
attempts than incentivized human persuaders, demonstrating superior persuasive
capabilities in both truthful (toward correct answers) and deceptive (toward
incorrect answers) contexts. We also find that LLM persuaders significantly
increased quiz takers' accuracy, leading to higher earnings, when steering quiz
takers toward correct answers, and significantly decreased their accuracy,
leading to lower earnings, when steering them toward incorrect answers.
Overall, our findings suggest that AI's persuasion capabilities already exceed
those of humans that have real-money bonuses tied to performance. Our findings
of increasingly capable AI persuaders thus underscore the urgency of emerging
alignment and governance frameworks.

05 Oct 2025

We establish the conditions under which a conservation law associated with a non-invertible operator may be realized as a symmetry in quantum mechanics. As established by Wigner, all quantum symmetries must be represented by either unitary or antiunitary transformations. Relinquishing an implicit assumption of invertibility, we demonstrate that the fundamental invariance of quantum transition probabilities under the application of symmetries mandates that all non-invertible symmetries may only correspond to {\it projective} unitary or antiunitary transformations, i.e., {\it partial isometries}. This extends the notion of physical states beyond conventional rays in Hilbert space to equivalence classes in an {\it extended, gauged Hilbert space}, thereby broadening the traditional understanding of symmetry transformations in quantum theory. We discuss consequences of this result and explicitly illustrate how, in simple model systems, whether symmetries be invertible or non-invertible may be inextricably related to the particular boundary conditions that are being used.

22 Oct 2018


Neural sequence models are widely used to model time-series data. Equally ubiquitous is the usage of beam search (BS) as an approximate inference algorithm to decode output sequences from these models. BS explores the search space in a greedy left-right fashion retaining only the top-B candidates - resulting in sequences that differ only slightly from each other. Producing lists of nearly identical sequences is not only computationally wasteful but also typically fails to capture the inherent ambiguity of complex AI tasks. To overcome this problem, we propose Diverse Beam Search (DBS), an alternative to BS that decodes a list of diverse outputs by optimizing for a diversity-augmented objective. We observe that our method finds better top-1 solutions by controlling for the exploration and exploitation of the search space - implying that DBS is a better search algorithm. Moreover, these gains are achieved with minimal computational or memory over- head as compared to beam search. To demonstrate the broad applicability of our method, we present results on image captioning, machine translation and visual question generation using both standard quantitative metrics and qualitative human studies. Further, we study the role of diversity for image-grounded language generation tasks as the complexity of the image changes. We observe that our method consistently outperforms BS and previously proposed techniques for diverse decoding from neural sequence models.

12 Aug 2025
Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by modeling the temporal order of actions, but has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining unseen "What if" scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. We conduct extensive experiments on procedure-aware tasks, including temporal action segmentation, error detection, action phase classification, frame retrieval, multi-instance retrieval, and action recognition. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals, and achieve significant improvements on multiple tasks.
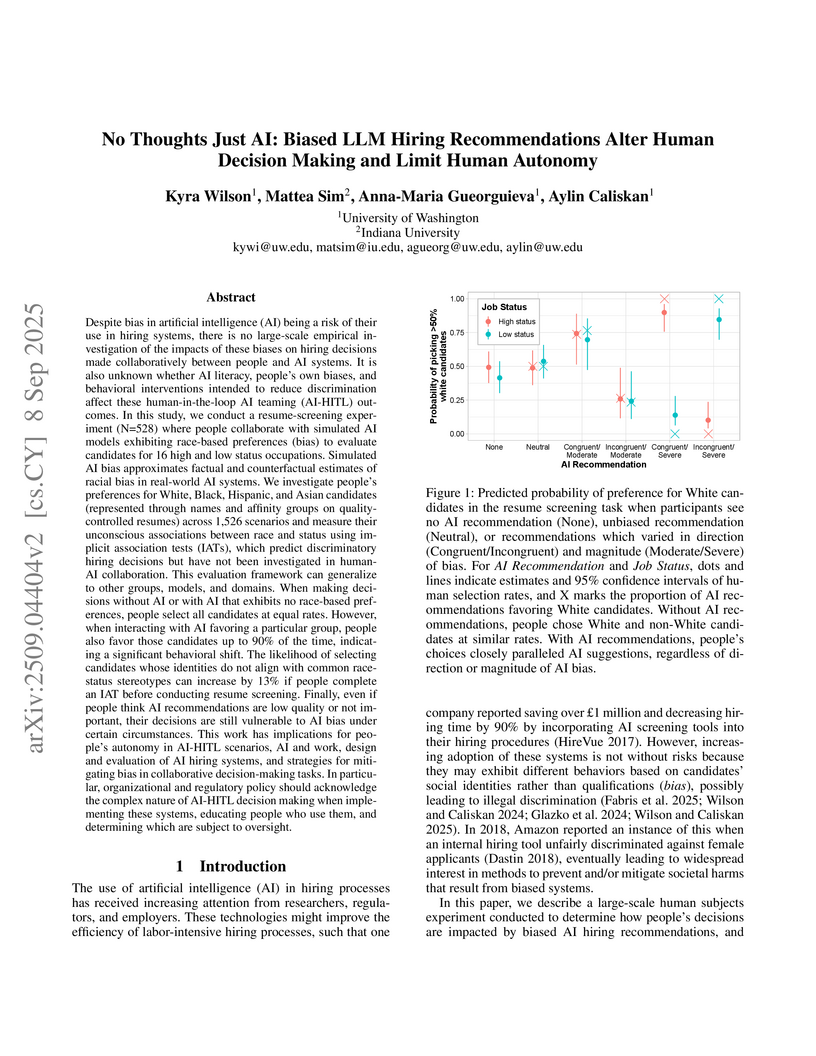
08 Sep 2025

Researchers at the University of Washington empirically investigated how biased AI hiring recommendations impact human decision-making, revealing that humans propagate AI biases up to 90% of the time. The study demonstrated that completing an Implicit Association Test (IAT) prior to decision-making increased stereotype-incongruent choices by over 12% in certain high-stakes scenarios.

24 Sep 2025
This comprehensive review systematically synthesizes theoretical and computational approaches to complex network robustness and resilience, categorizing research into design, early-warning, and adaptive response phases. It provides a comparative analysis of network dismantling algorithms on diverse real-world systems and offers practical tools for the research community.

09 Sep 2025

BOLT is an oblivious map accelerator that utilizes secure High-Bandwidth Memory (HBM) to deliver O(1) + O(log log N) bandwidth and constant round overhead, a substantial improvement over prior OMAPs. Its self-hosted architecture and algorithm-hardware co-design enable up to 480x faster query times and 279x faster initialization compared to state-of-the-art software OMAPs, reducing normalized slowdown by up to 6338x.

22 Sep 2025
Automated Knowledge Graph Construction using Large Language Models and Sentence Complexity Modelling
Automated Knowledge Graph Construction using Large Language Models and Sentence Complexity Modelling
We introduce CoDe-KG, an open-source, end-to-end pipeline for extracting sentence-level knowledge graphs by combining robust coreference resolution with syntactic sentence decomposition. Using our model, we contribute a dataset of over 150,000 knowledge triples, which is open source. We also contribute a training corpus of 7248 rows for sentence complexity, 190 rows of gold human annotations for co-reference resolution using open source lung-cancer abstracts from PubMed, 900 rows of gold human annotations for sentence conversion policies, and 398 triples of gold human annotations. We systematically select optimal prompt-model pairs across five complexity categories, showing that hybrid chain-of-thought and few-shot prompting yields up to 99.8% exact-match accuracy on sentence simplification. On relation extraction (RE), our pipeline achieves 65.8% macro-F1 on REBEL, an 8-point gain over the prior state of the art, and 75.7% micro-F1 on WebNLG2, while matching or exceeding performance on Wiki-NRE and CaRB. Ablation studies demonstrate that integrating coreference and decomposition increases recall on rare relations by over 20%. Code and dataset are available at this https URL

06 Nov 2024
The massive population election simulation aims to model the preferences of
specific groups in particular election scenarios. It has garnered significant
attention for its potential to forecast real-world social trends. Traditional
agent-based modeling (ABM) methods are constrained by their ability to
incorporate complex individual background information and provide interactive
prediction results. In this paper, we introduce ElectionSim, an innovative
election simulation framework based on large language models, designed to
support accurate voter simulations and customized distributions, together with
an interactive platform to dialogue with simulated voters. We present a
million-level voter pool sampled from social media platforms to support
accurate individual simulation. We also introduce PPE, a poll-based
presidential election benchmark to assess the performance of our framework
under the U.S. presidential election scenario. Through extensive experiments
and analyses, we demonstrate the effectiveness and robustness of our framework
in U.S. presidential election simulations.

20 Sep 2025
Almost 30% of prostate cancer (PCa) patients undergoing radical prostatectomy (RP) experience biochemical recurrence (BCR), characterized by increased prostate specific antigen (PSA) and associated with increased mortality. Accurate early prediction of BCR, at the time of RP, would contribute to prompt adaptive clinical decision-making and improved patient outcomes. In this work, we propose prostate cancer BCR prediction via fused multi-modal embeddings (PROFUSEme), which learns cross-modal interactions of clinical, radiology, and pathology data, following an intermediate fusion configuration in combination with Cox Proportional Hazard regressors. Quantitative evaluation of our proposed approach reveals superior performance, when compared with late fusion configurations, yielding a mean C-index of 0.861 () on the internal 5-fold nested cross-validation framework, and a C-index of 0.7107 on the hold out data of CHIMERA 2025 challenge validation leaderboard.
There are no more papers matching your filters at the moment.
