
29 Sep 2022

The paper proposes and empirically validates two 8-bit floating-point (FP8) formats, E4M3 and E5M2, for deep learning. These formats enable training and inference with 8-bit precision while consistently matching the accuracy of 16-bit baselines across diverse models and tasks, including large language models.

21 Jul 2022
Researchers at Arm demonstrate that federated learning suffers substantial accuracy losses, up to approximately 55%, when client data is highly non-IID, attributing this to weight divergence between local and global models. They establish Earth Mover's Distance as a quantifiable metric for data skewness and propose a data-sharing strategy that improves accuracy on challenging non-IID tasks, such as CIFAR-10, by about 30% absolute points with minimal centralized data.

09 May 2020






Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and five orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. In this paper, we present our benchmarking method for evaluating ML inference systems. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf prescribes a set of rules and best practices to ensure comparability across systems with wildly differing architectures. The first call for submissions garnered more than 600 reproducible inference-performance measurements from 14 organizations, representing over 30 systems that showcase a wide range of capabilities. The submissions attest to the benchmark's flexibility and adaptability.

20 May 2025
Text-to-audio systems, while increasingly performant, are slow at inference
time, thus making their latency unpractical for many creative applications. We
present Adversarial Relativistic-Contrastive (ARC) post-training, the first
adversarial acceleration algorithm for diffusion/flow models not based on
distillation. While past adversarial post-training methods have struggled to
compare against their expensive distillation counterparts, ARC post-training is
a simple procedure that (1) extends a recent relativistic adversarial
formulation to diffusion/flow post-training and (2) combines it with a novel
contrastive discriminator objective to encourage better prompt adherence. We
pair ARC post-training with a number optimizations to Stable Audio Open and
build a model capable of generating 12s of 44.1kHz stereo audio in
75ms on an H100, and 7s on a mobile edge-device, the fastest
text-to-audio model to our knowledge.

14 Feb 2018
Researchers from Arm and Stanford University conducted a comprehensive evaluation of neural network architectures for always-on keyword spotting on resource-constrained microcontrollers. Their study identified Depthwise Separable Convolutional Neural Networks (DS-CNNs) as the most efficient, achieving up to 95.4% accuracy, and validated 8-bit quantization as a practical method for reducing model size and improving deployment on edge devices.

20 May 2019
The Straight-Through Estimator (STE) is widely used for back-propagating
gradients through the quantization function, but the STE technique lacks a
complete theoretical understanding. We propose an alternative methodology
called alpha-blending (AB), which quantizes neural networks to low-precision
using stochastic gradient descent (SGD). Our method (AB) avoids STE
approximation by replacing the quantized weight in the loss function by an
affine combination of the quantized weight w_q and the corresponding
full-precision weight w with non-trainable scalar coefficient and
. During training, is gradually increased from 0 to 1; the
gradient updates to the weights are through the full-precision term,
, of the affine combination; the model is converted from
full-precision to low-precision progressively. To evaluate the method, a 1-bit
BinaryNet on CIFAR10 dataset and 8-bits, 4-bits MobileNet v1, ResNet_50 v1/2 on
ImageNet dataset are trained using the alpha-blending approach, and the
evaluation indicates that AB improves top-1 accuracy by 0.9%, 0.82% and 2.93%
respectively compared to the results of STE based quantization.

28 Aug 2024
We present a novel approach to the 3D sound source localization task for distributed ad-hoc microphone arrays by formulating it as a set-to-set regression problem. By training a multi-modal masked autoencoder model that operates on audio recordings and microphone coordinates, we show that such a formulation allows for accurate localization of the sound source, by reconstructing coordinates masked in the input. Our approach is flexible in the sense that a single model can be used with an arbitrary number of microphones, even when a subset of audio recordings and microphone coordinates are missing. We test our method on simulated and real-world recordings of music and speech in indoor environments, and demonstrate competitive performance compared to both classical and other learning based localization methods.

09 Aug 2022
A new time delay of arrival (TDOA) estimation method extends the Generalized Cross-Correlation with Phase Transform (GCC-PHAT) by integrating shift equivariant neural networks, improving robustness in noisy and reverberant environments. The approach achieves up to 50% lower Mean Absolute Error and higher accuracy compared to traditional GCC-PHAT across various challenging acoustic conditions.

06 Apr 2022
This paper presents the first industry-standard open-source machine learning (ML) benchmark to allow perfor mance and accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. It comprises a suite of models that operate with standard data sets, quality metrics and run rules. We describe the design and implementation of this domain-specific ML benchmark. The current benchmark version comes as a mobile app for different computer vision and natural language processing tasks. The benchmark also supports non-smartphone devices, such as laptops and mobile PCs. Benchmark results from the first two rounds reveal the overwhelming complexity of the underlying mobile ML system stack, emphasizing the need for transparency in mobile ML performance analysis. The results also show that the strides being made all through the ML stack improve performance. Within six months, offline throughput improved by 3x, while latency reduced by as much as 12x. ML is an evolving field with changing use cases, models, data sets and quality targets. MLPerf Mobile will evolve and serve as an open-source community framework to guide research and innovation for mobile AI.

31 Oct 2025


MLPerf Automotive introduces the first standardized public benchmark for evaluating machine learning systems in autonomous vehicles, addressing unique industry requirements for safety, real-time performance, and longevity. It defines specific perception tasks using relevant datasets and stringent metrics like 99.9% tail latency, facilitating fair and reproducible comparisons across diverse hardware and software.

27 Aug 2025

Memory allocation, though constituting only a small portion of the executed code, can have a "butterfly effect" on overall program performance, leading to significant and far-reaching impacts. Despite accounting for just approximately 5% of total instructions, memory allocation can result in up to a 2.7x performance variation depending on the allocator used. This effect arises from the complexity of memory allocation in modern multi-threaded multi-core systems, where allocator metadata becomes intertwined with user data, leading to cache pollution or increased cross-thread synchronization overhead. Offloading memory allocators to accelerators, e.g., Mallacc and Memento, is a potential direction to improve the allocator performance and mitigate cache pollution. However, these accelerators currently have limited support for multi-threaded applications, and synchronization between cores and accelerators remains a significant challenge.
We present SpeedMalloc, using a lightweight support-core to process memory allocation tasks in multi-threaded applications. The support-core is a lightweight programmable processor with efficient cross-core data synchronization and houses all allocator metadata in its own caches. This design minimizes cache conflicts with user data and eliminates the need for cross-core metadata synchronization. In addition, using a general-purpose core instead of domain-specific accelerators makes SpeedMalloc capable of adopting new allocator designs. We compare SpeedMalloc with state-of-the-art software and hardware allocators, including Jemalloc, TCMalloc, Mimalloc, Mallacc, and Memento. SpeedMalloc achieves 1.75x, 1.18x, 1.15x, 1.23x, and 1.18x speedups on multithreaded workloads over these five allocators, respectively.
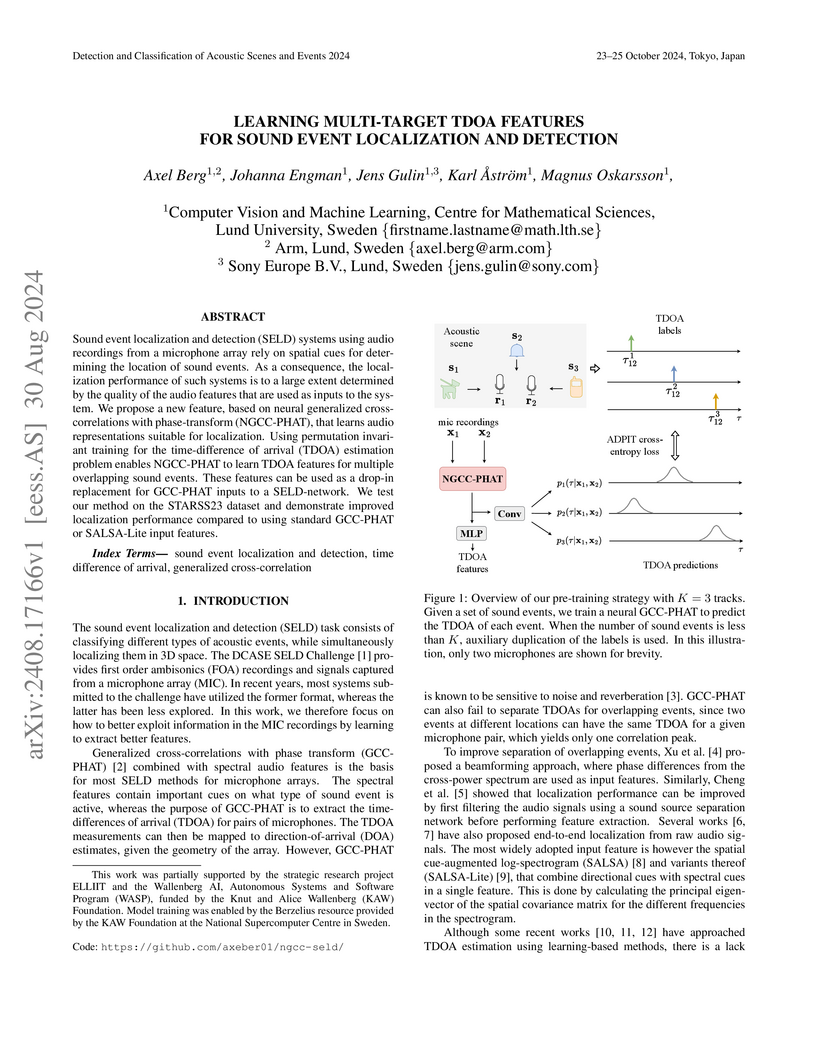
30 Aug 2024
Sound event localization and detection (SELD) systems using audio recordings from a microphone array rely on spatial cues for determining the location of sound events. As a consequence, the localization performance of such systems is to a large extent determined by the quality of the audio features that are used as inputs to the system. We propose a new feature, based on neural generalized cross-correlations with phase-transform (NGCC-PHAT), that learns audio representations suitable for localization. Using permutation invariant training for the time-difference of arrival (TDOA) estimation problem enables NGCC-PHAT to learn TDOA features for multiple overlapping sound events. These features can be used as a drop-in replacement for GCC-PHAT inputs to a SELD-network. We test our method on the STARSS23 dataset and demonstrate improved localization performance compared to using standard GCC-PHAT or SALSA-Lite input features.

20 Nov 2024


The standardization of an interface for dense linear algebra operations in the BLAS standard has enabled interoperability between different linear algebra libraries, thereby boosting the success of scientific computing, in particular in scientific HPC. Despite numerous efforts in the past, the community has not yet agreed on a standardization for sparse linear algebra operations due to numerous reasons. One is the fact that sparse linear algebra objects allow for many different storage formats, and different hardware may favor different storage formats. This makes the definition of a FORTRAN-style all-circumventing interface extremely challenging. Another reason is that opposed to dense linear algebra functionality, in sparse linear algebra, the size of the sparse data structure for the operation result is not always known prior to the information. Furthermore, as opposed to the standardization effort for dense linear algebra, we are late in the technology readiness cycle, and many production-ready software libraries using sparse linear algebra routines have implemented and committed to their own sparse BLAS interface. At the same time, there exists a demand for standardization that would improve interoperability, and sustainability, and allow for easier integration of building blocks. In an inclusive, cross-institutional effort involving numerous academic institutions, US National Labs, and industry, we spent two years designing a hardware-portable interface for basic sparse linear algebra functionality that serves the user needs and is compatible with the different interfaces currently used by different vendors. In this paper, we present a C++ API for sparse linear algebra functionality, discuss the design choices, and detail how software developers preserve a lot of freedom in terms of how to implement functionality behind this API.

03 Aug 2020
Matrix multiplications between asymmetric bit-width operands, especially
between 8- and 4-bit operands are likely to become a fundamental kernel of many
important workloads including neural networks and machine learning. While
existing SIMD matrix multiplication instructions for symmetric bit-width
operands can support operands of mixed precision by zero- or sign-extending the
narrow operand to match the size of the other operands, they cannot exploit the
benefit of narrow bit-width of one of the operands. We propose a new SIMD
matrix multiplication instruction that uses mixed precision on its inputs (8-
and 4-bit operands) and accumulates product values into narrower 16-bit output
accumulators, in turn allowing the SIMD operation at 128-bit vector width to
process a greater number of data elements per instruction to improve processing
throughput and memory bandwidth utilization without increasing the register
read- and write-port bandwidth in CPUs. The proposed asymmetric-operand-size
SIMD instruction offers 2x improvement in throughput of matrix multiplication
in comparison to throughput obtained using existing symmetric-operand-size
instructions while causing negligible (0.05%) overflow from 16-bit accumulators
for representative machine learning workloads. The asymmetric-operand-size
instruction not only can improve matrix multiplication throughput in CPUs, but
also can be effective to support multiply-and-accumulate (MAC) operation
between 8- and 4-bit operands in state-of-the-art DNN hardware accelerators
(e.g., systolic array microarchitecture in Google TPU, etc.) and offer similar
improvement in matrix multiply performance seamlessly without violating the
various implementation constraints. We demonstrate how a systolic array
architecture designed for symmetric-operand-size instructions could be modified
to support an asymmetric-operand-sized instruction.

31 Mar 2023



Cloud FPGAs strike an alluring balance between computational efficiency, energy efficiency, and cost. It is the flexibility of the FPGA architecture that enables these benefits, but that very same flexibility that exposes new security vulnerabilities. We show that a remote attacker can recover "FPGA pentimenti" - long-removed secret data belonging to a prior user of a cloud FPGA. The sensitive data constituting an FPGA pentimento is an analog imprint from bias temperature instability (BTI) effects on the underlying transistors. We demonstrate how this slight degradation can be measured using a time-to-digital (TDC) converter when an adversary programs one into the target cloud FPGA.
This technique allows an attacker to ascertain previously safe information on cloud FPGAs, even after it is no longer explicitly present. Notably, it can allow an attacker who knows a non-secret "skeleton" (the physical structure, but not the contents) of the victim's design to (1) extract proprietary details from an encrypted FPGA design image available on the AWS marketplace and (2) recover data loaded at runtime by a previous user of a cloud FPGA using a known design. Our experiments show that BTI degradation (burn-in) and recovery are measurable and constitute a security threat to commercial cloud FPGAs.

26 Feb 2021
Hardware/Software (HW/SW) co-designed processors provide a promising solution to the power and complexity problems of the modern microprocessors by keeping their hardware simple. Moreover, they employ several runtime optimizations to improve the performance. One of the most potent optimizations, vectorization, has been utilized by modern microprocessors, to exploit the data level parallelism through SIMD accelerators. Due to their hardware simplicity, these accelerators have evolved in terms of width from 64-bit vectors in Intel MMX to 512-bit wide vector units in Intel Xeon Phi and AVX-512. Although SIMD accelerators are simple in terms of hardware design, code generation for them has always been a challenge. Moreover, increasing vector lengths with each new generation add to this complexity.
This paper explores the scalability of SIMD accelerators from the code generation point of view. We discover that the SIMD accelerators remain underutilized at higher vector lengths mainly due to: a) reduced dynamic instruction stream coverage for vectorization and b) increase in permutations. Both of these factors can be attributed to the rigidness of the SIMD architecture. We propose a novel SIMD architecture that possesses the flexibility needed to support higher vector lengths. Furthermore, we propose Variable Length Vectorization and Selective Writing in a HW/SW co-designed environment to transparently target the flexibility of the proposed architecture. We evaluate our proposals using a set of SPECFP2006 and Physicsbench applications. Our experimental results show an average dynamic instruction reduction of 31% and 40% and an average speed up of 13% and 10% for SPECFP2006 and Physicsbench respectively, for 512-bit vector length, over the scalar baseline code.

27 Oct 2023
The security goals of cloud providers and users include memory confidentiality and integrity, which requires implementing Replay-Attack protection (RAP). RAP can be achieved using integrity trees or mutually authenticated channels. Integrity trees incur significant performance overheads and are impractical for protecting large memories. Mutually authenticated channels have been proposed only for packetized memory interfaces that address only a very small niche domain and require fundamental changes to memory system architecture. We propose SecDDR, a low-cost RAP that targets direct-attached memories, like DDRx. SecDDR avoids memory-side data authentication, and thus, only adds a small amount of logic to memory components and does not change the underlying DDR protocol, making it practical for widespread adoption. In contrast to prior mutual authentication proposals, which require trusting the entire memory module, SecDDR targets untrusted modules by placing its limited security logic on the DRAM die (or package) of the ECC chip. Our evaluation shows that SecDDR performs within 1% of an encryption-only memory without RAP and that SecDDR provides 18.8% and 7.8% average performance improvements (up to 190.4% and 24.8%) relative to a 64-ary integrity tree and an authenticated channel, respectively.

24 Dec 2021

This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.

06 May 2022
Interactive theorem proving software is typically designed around a trusted
proof-checking kernel, the sole system component capable of authenticating
theorems. Untrusted automation procedures reside outside of the kernel, and
drive it to deduce new theorems via an API. Kernel and untrusted automation are
typically implemented in the same programming language -- the "meta-language"
-- usually some functional programming language in the ML family. This strategy
-- introduced by Milner in his LCF proof assistant -- is a reliability
mechanism, aiming to ensure that any purported theorem produced by the system
is indeed entailed by the theory within the logic.
Changing tack, operating systems are also typically designed around a trusted
kernel, a privileged component responsible for -- amongst other things --
mediating interaction betwixt user-space software and hardware. Untrusted
processes interact with the system by issuing kernel system calls across a
hardware privilege boundary. In this way, the operating system kernel
supervises user-space processes.
Though ostensibly very different, squinting, we see that the two kinds of
kernel are tasked with solving the same task: enforcing system invariants in
the face of unbounded interaction with untrusted code. Yet, the two solutions
to solving this problem, employed by the respective kinds of kernel, are very
different.
In this abstract, we explore designing proof-checking kernels as supervisory
software, where separation between kernel and untrusted code is enforced by
privilege, not programming language module boundaries and type abstraction. We
describe work on the Supervisionary proof-checking kernel, and briefly sketch
its unique system interface. We then describe some potential uses of the
Supervisionary kernel.

27 Oct 2023
The security goals of cloud providers and users include memory
confidentiality and integrity, which requires implementing Replay-Attack
protection (RAP). RAP can be achieved using integrity trees or mutually
authenticated channels. Integrity trees incur significant performance overheads
and are impractical for protecting large memories. Mutually authenticated
channels have been proposed only for packetized memory interfaces that address
only a very small niche domain and require fundamental changes to memory system
architecture. We propose SecDDR, a low-cost RAP that targets direct-attached
memories, like DDRx. SecDDR avoids memory-side data authentication, and thus,
only adds a small amount of logic to memory components and does not change the
underlying DDR protocol, making it practical for widespread adoption. In
contrast to prior mutual authentication proposals, which require trusting the
entire memory module, SecDDR targets untrusted modules by placing its limited
security logic on the DRAM die (or package) of the ECC chip. Our evaluation
shows that SecDDR performs within 1% of an encryption-only memory without RAP
and that SecDDR provides 18.8% and 7.8% average performance improvements (up to
190.4% and 24.8%) relative to a 64-ary integrity tree and an authenticated
channel, respectively.
There are no more papers matching your filters at the moment.
