
14 Oct 2025

Introduction: Requirements engineering faces challenges due to the handling of increasingly complex software systems. These challenges can be addressed using generative AI. Given that GenAI based RE has not been systematically analyzed in detail, this review examines related research, focusing on trends, methodologies, challenges, and future directions. Methods: A systematic methodology for paper selection, data extraction, and feature analysis is used to comprehensively review 238 articles published from 2019 to 2025 and available from major academic databases. Results: Generative pretrained transformer models dominate current applications (67.3%), but research remains unevenly distributed across RE phases, with analysis (30.0%) and elicitation (22.1%) receiving the most attention, and management (6.8%) underexplored. Three core challenges: reproducibility (66.8%), hallucinations (63.4%), and interpretability (57.1%) form a tightly interlinked triad affecting trust and consistency. Strong correlations (35% cooccurrence) indicate these challenges must be addressed holistically. Industrial adoption remains nascent, with over 90% of studies corresponding to early stage development and only 1.3% reaching production level integration. Conclusions: Evaluation practices show maturity gaps, limited tool and dataset availability, and fragmented benchmarking approaches. Despite the transformative potential of GenAI based RE, several barriers hinder practical adoption. The strong correlations among core challenges demand specialized architectures targeting interdependencies rather than isolated solutions. The limited deployment reflects systemic bottlenecks in generalizability, data quality, and scalable evaluation methods. Successful adoption requires coordinated development across technical robustness, methodological maturity, and governance integration.

21 Jul 2023
 Carnegie Mellon University
Carnegie Mellon University GoogleJapan Advanced Institute of Science and Technology
GoogleJapan Advanced Institute of Science and Technology Emory University
Emory University Mohamed bin Zayed University of Artificial Intelligence
Mohamed bin Zayed University of Artificial Intelligence HKUSTKorea Advanced Institute of Science and TechnologyUniversity of TsukubaNara Institute of Science and TechnologyUniversitas IndonesiaTelkom UniversityInstitut Teknologi BandungKumamoto UniversityBloombergBina Nusantara UniversityProsa.aiKanda University of International StudiesTanjungpura UniversityJULOAI-Research.idBahasa.aiUniversitas Al Azhar IndonesiaSurface DataState University of Medan
HKUSTKorea Advanced Institute of Science and TechnologyUniversity of TsukubaNara Institute of Science and TechnologyUniversitas IndonesiaTelkom UniversityInstitut Teknologi BandungKumamoto UniversityBloombergBina Nusantara UniversityProsa.aiKanda University of International StudiesTanjungpura UniversityJULOAI-Research.idBahasa.aiUniversitas Al Azhar IndonesiaSurface DataState University of Medan
We present NusaCrowd, a collaborative initiative to collect and unify existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have brought together 137 datasets and 118 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their value is demonstrated through multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and the local languages of Indonesia. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and the local languages of Indonesia. Our work strives to advance natural language processing (NLP) research for languages that are under-represented despite being widely spoken.

15 Jan 2025


4D Flow Magnetic Resonance Imaging (4D Flow MRI) is a non-invasive technique for volumetric, time-resolved blood flow quantification. However, apparent trade-offs between acquisition time, image noise, and resolution limit clinical applicability. In particular, in regions of highly transient flow, coarse temporal resolution can hinder accurate capture of physiologically relevant flow variations. To overcome these issues, post-processing techniques using deep learning have shown promising results to enhance resolution post-scan using so-called super-resolution networks. However, while super-resolution has been focusing on spatial upsampling, temporal super-resolution remains largely unexplored. The aim of this study was therefore to implement and evaluate a residual network for temporal super-resolution 4D Flow MRI. To achieve this, an existing spatial network (4DFlowNet) was re-designed for temporal upsampling, adapting input dimensions, and optimizing internal layer structures. Training and testing were performed using synthetic 4D Flow MRI data originating from patient-specific in-silico models, as well as using in-vivo datasets. Overall, excellent performance was achieved with input velocities effectively denoised and temporally upsampled, with a mean absolute error (MAE) of 1.0 cm/s in an unseen in-silico setting, outperforming deterministic alternatives (linear interpolation MAE = 2.3 cm/s, sinc interpolation MAE = 2.6 cm/s). Further, the network synthesized high-resolution temporal information from unseen low-resolution in-vivo data, with strong correlation observed at peak flow frames. As such, our results highlight the potential of utilizing data-driven neural networks for temporal super-resolution 4D Flow MRI, enabling high-frame-rate flow quantification without extending acquisition times beyond clinically acceptable limits.

09 Jul 2025
Large Language Models (LLMs) often generate scientifically plausible but factually invalid information, a challenge we term the "plausibility-validity gap," particularly in specialized domains like chemistry. This paper presents a systematic methodology to bridge this gap by developing a specialized scientific assistant. We utilized the Magistral Small model, noted for its integrated reasoning capabilities, and fine-tuned it using Low-Rank Adaptation (LoRA). A key component of our approach was the creation of a "dual-domain dataset," a comprehensive corpus curated from various sources encompassing both molecular properties and chemical reactions, which was standardized to ensure quality. Our evaluation demonstrates that the fine-tuned model achieves significant improvements over the baseline model in format adherence, chemical validity of generated molecules, and the feasibility of proposed synthesis routes. The results indicate a hierarchical learning pattern, where syntactic correctness is learned more readily than chemical possibility and synthesis feasibility. While a comparative analysis with human experts revealed competitive performance in areas like chemical creativity and reasoning, it also highlighted key limitations, including persistent errors in stereochemistry, a static knowledge cutoff, and occasional reference hallucination. This work establishes a viable framework for adapting generalist LLMs into reliable, specialized tools for chemical research, while also delineating critical areas for future improvement.

21 Sep 2024

Technical debt (TD) represents the long-term costs associated with suboptimal design or code decisions in software development, often made to meet short-term delivery goals. Self-Admitted Technical Debt (SATD) occurs when developers explicitly acknowledge these trade-offs in the codebase, typically through comments or annotations. Automated detection of SATD has become an increasingly important research area, particularly with the rise of natural language processing (NLP), machine learning (ML), and deep learning (DL) techniques that aim to streamline SATD detection.
This systematic literature review provides a comprehensive analysis of SATD detection approaches published between 2014 and 2024, focusing on the evolution of techniques from NLP-based models to more advanced ML, DL, and Transformers-based models such as BERT. The review identifies key trends in SATD detection methodologies and tools, evaluates the effectiveness of different approaches using metrics like precision, recall, and F1-score, and highlights the primary challenges in this domain, including dataset heterogeneity, model generalizability, and the explainability of models.
The findings suggest that while early NLP methods laid the foundation for SATD detection, more recent advancements in DL and Transformers models have significantly improved detection accuracy. However, challenges remain in scaling these models for broader industrial use. This SLR offers insights into current research gaps and provides directions for future work, aiming to improve the robustness and practicality of SATD detection tools.

29 Jun 2025
VALID-Mol is a systematic framework that enhances the reliability of Large Language Model (LLM) outputs for molecular design by integrating systematic prompt engineering, multi-layered chemical validation, and domain-specific fine-tuning. It achieves a 99.8% rate of chemically valid outputs and generates molecules with significant predicted property improvements.

25 Jun 2025
The Russian invasion of Ukraine has fundamentally altered the information technology (IT) risk landscape, particularly in cloud computing environments. This paper examines how this geopolitical conflict has accelerated data sovereignty concerns, transformed cybersecurity paradigms, and reshaped cloud infrastructure strategies worldwide. Through an analysis of documented cyber operations, regulatory responses, and organizational adaptations between 2022 and early 2025, this research demonstrates how the conflict has served as a catalyst for a broader reassessment of IT risk. The research reveals that while traditional IT risk frameworks offer foundational guidance, their standard application may inadequately address the nuances of state-sponsored threats, conflicting data governance regimes, and the weaponization of digital dependencies without specific geopolitical augmentation. The contribution of this paper lies in its focused synthesis and strategic adaptation of existing best practices into a multi-layered approach. This approach uniquely synergizes resilient cloud architectures (including sovereign and hybrid models), enhanced data-centric security strategies (such as advanced encryption and privacy-enhancing technologies), and geopolitically-informed governance to build digital resilience. The interplay between these layers, emphasizing how geopolitical insights directly shape architectural and security choices beyond standard best practices-particularly by integrating the human element, including personnel vulnerabilities and expertise, as a core consideration in technical design and operational management-offers a more robust defense against the specific, multifaceted risks arising from geopolitical conflict in increasingly fractured digital territories.

25 Jun 2025
The convergence of IT and OT has created hyper-connected ICS, exposing critical infrastructure to a new class of adaptive, intelligent adversaries that render static defenses obsolete. Existing security paradigms often fail to address a foundational "Trinity of Trust," comprising the fidelity of the system model, the integrity of synchronizing data, and the resilience of the analytical engine against sophisticated evasion. This paper introduces the ARC framework, a method for achieving analytical resilience through an autonomous, closed-loop hardening process. ARC establishes a perpetual co-evolutionary arms race within the high-fidelity sandbox of a F-SCDT. A DRL agent, the "Red Agent," is formalized and incentivized to autonomously discover stealthy, physically-plausible attack paths that maximize process disruption while evading detection. Concurrently, an ensemble-based "Blue Agent" defender is continuously hardened via adversarial training against the evolving threats discovered by its adversary. This co-evolutionary dynamic forces both agents to become progressively more sophisticated, enabling the system to autonomously probe and patch its own vulnerabilities. Experimental validation on both the TEP and the SWaT testbeds demonstrates the framework's superior performance. A comprehensive ablation study, supported by extensive visualizations including ROC curves and SHAP plots, reveals that the co-evolutionary process itself is responsible for a significant performance increase in detecting novel attacks. By integrating XAI to ensure operator trust and proposing a scalable F-ARC architecture, this work presents ARC not merely as an improvement, but as a necessary paradigm shift toward dynamic, self-improving security for the future of critical infrastructure.
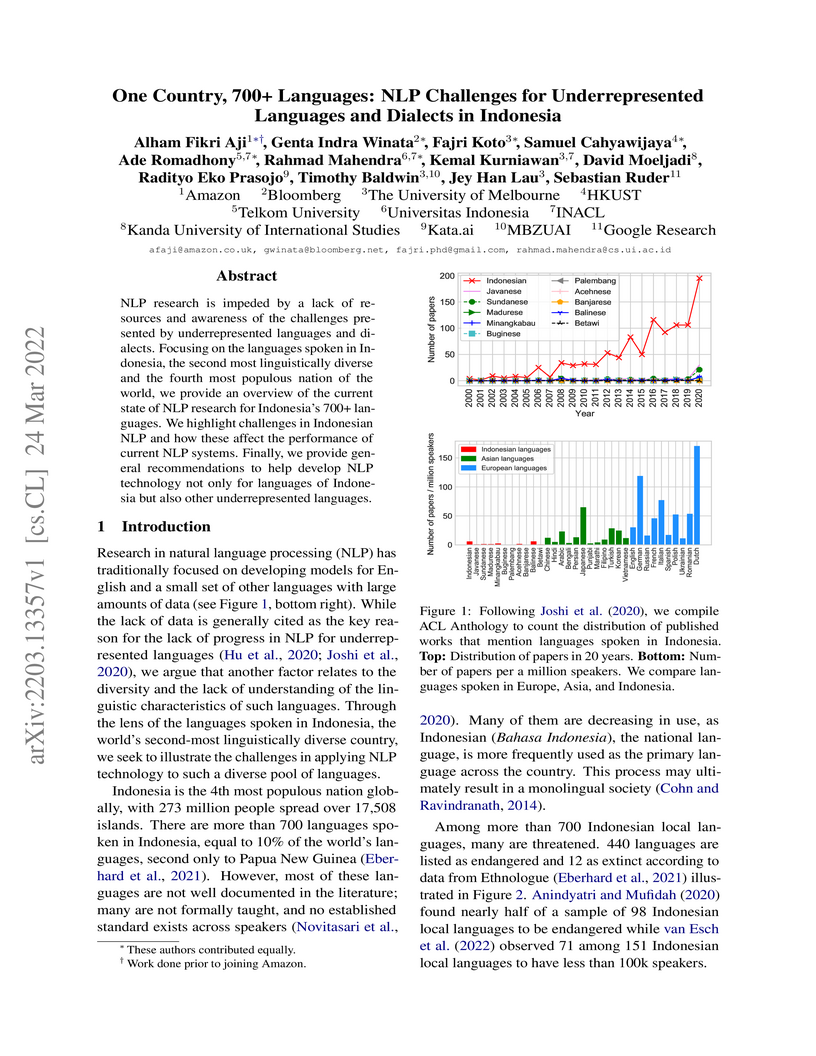
24 Mar 2022
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
NLP research is impeded by a lack of resources and awareness of the challenges presented by underrepresented languages and dialects. Focusing on the languages spoken in Indonesia, the second most linguistically diverse and the fourth most populous nation of the world, we provide an overview of the current state of NLP research for Indonesia's 700+ languages. We highlight challenges in Indonesian NLP and how these affect the performance of current NLP systems. Finally, we provide general recommendations to help develop NLP technology not only for languages of Indonesia but also other underrepresented languages.

01 Sep 2025
Quantum batteries, which can be seen as energy- or state-storage devices exploiting coherence and other quantum effects, are sensitive to environmental noise. Here we show that, when suitably engineered, environmental noise can induce a "Zeno-like" stabilization of the charging process in a spin-chain quantum battery. To explore this interplay, we study a system size N=6, which provides large storage capacity with moderate computational cost, and more importantly, allows the stored energy to become almost fully extractable since the ergotropy nearly coincides with the total capacity. We analyze three local noise channels: bit flip, phase flip, and bit phase flip. We vary the strength of each channel to emulate frequent environmental monitoring, reminiscent of the quantum Zeno effect, and track its influence on the charging dynamics and stored energy. The phase-flip channel slows charging under strong noise but stabilizes stored energy and ergotropy. The bit-flip channel enables faster charging but saturates at low capacities, while the bit phase flip channel combines both features. In the discharging stage, different noise channels lead to distinct release dynamics, showing that noise can paradoxically enhance and stabilize quantum battery operation.

07 Apr 2019
Globally distributed groups require collaborative systems to support their
work. Besides being able to support the teamwork, these systems also should
promote well-being and maximize the human potential that leads to an engaging
system and joyful experience. Designing such system is a significant challenge
and requires a thorough understanding of group work. We used the field theory
as a lens to view the essential aspects of group motivation and then utilized
collaboration personas to analyze the elements of group work. We integrated
well-being determinants as engagement factors to develop a group-centered
framework for digital collaboration in a global setting. Based on the outcomes,
we proposed a conceptual framework to design an engaging collaborative system
and recommend system values that can be used to evaluate the system further

10 Jul 2020
This paper examines the use of artificial neural network approach in
identifying the origin of clove buds based on metabolites composition.
Generally, large data sets are critical for accurate identification. Machine
learning with large data sets lead to precise identification based on origins.
However, clove buds uses small data sets due to lack of metabolites composition
and their high cost of extraction. The results show that backpropagation and
resilient propagation with one and two hidden layers identifies clove buds
origin accurately. The backpropagation with one hidden layer offers 99.91% and
99.47% for training and testing data sets, respectively. The resilient
propagation with two hidden layers offers 99.96% and 97.89% accuracy for
training and testing data sets, respectively.

03 Dec 2020
We consider Hoare-style verification for the graph programming language GP 2.
In previous work, graph properties were specified by so-called E-conditions
which extend nested graph conditions. However, this type of assertions is not
easy to comprehend by programmers that are used to formal specifications in
standard first-order logic. In this paper, we present an approach to verify GP
2 programs with a standard first-order logic. We show how to construct a
strongest liberal postcondition with respect to a rule schema and a
precondition. We then extend this construction to obtain strongest liberal
postconditions for arbitrary loop-free programs. Compared with previous work,
this allows to reason about a vastly generalised class of graph programs. In
particular, many programs with nested loops can be verified with the new
calculus.

25 Mar 2022
Quantum annealing technologies aim to solve computational optimization and sampling problems. QPU (Quantum Processing Unit) machines such as the D-Wave system use the QUBO (Quadratic Unconstrained Binary Optimization) formula to define model optimization problems for quantum annealing. This machine uses quantum effects to speed up computing time better than classical computers. We propose a vehicle routing problem that can be formulated in the QUBO model as a combinatorial problem, which gives the possible route solutions increases exponentially. The solution aims to optimize the vehicle's journey to reach a destination. The study presents a QUBO formulation to solve traffic congestion problems on certain roads. The resulting route selection by optimizing the distribution of the flow of alternative road vehicles based on the weighting of road segments. Constraints formulated as a condition for the level of road density. The road weight parameter influences the cost function for each road choice. The simulations on the D-Wave quantum annealer show optimal results on the route deployment of several vehicles. So that each vehicle will be able to go through different road options and reduce road congestion accurately. This solution provides an opportunity to develop QUBO modeling for more complex vehicle routing problems for road congestion.

23 Sep 2024
In recent years, it has been observed that the center of gravity for the
volume of higher education has shifted to the Global South. However, research
indicates a widening disparity in the quality of higher education between the
Global South and the Global North. Although investments in higher education
within the Global South have increased, the rapid surge in student numbers has
resulted in a decline in public expenditure per student. For instance, the
student-to-teacher ratio in the Global South is significantly higher compared
to that in the Global North, which poses a substantial barrier to the
implementation of creative education. In response, Telkom University in
Indonesia has embarked on an experiment to enhance the quality of learning and
teaching by integrating large language models (LLMs) such as ChatGPT into five
of its courses-Mathematics, English, Computing, Computer Systems, and Creative
Media. This article elucidates the ongoing experimental plan and explores how
the integration of LLMs could contribute to addressing the challenges currently
faced by higher education in the Global South.

28 May 2024
To efficiently utilize the scarce wireless resource, the random access scheme
has been attaining renewed interest primarily in supporting the sporadic
traffic of a large number of devices encountered in the Internet of Things
(IoT). In this paper we investigate the performance of slotted ALOHA -- a
simple and practical random access scheme -- in connection with the grant-free
random access protocol applied for user-centric cell-free massive MIMO. More
specifically, we provide the expression of the sum-throughput under the
assumptions of the capture capability owned by the centralized detector in the
uplink. Further, a comparative study of user-centric cell-free massive MIMO
with other types of networks is provided, which allows us to identify its
potential and possible limitation. Our numerical simulations show that the
user-centric cell-free massive MIMO has a good trade-off between performance
and fronthaul load, especially at low activation probability regime.

13 Jul 2018
An attitude of satellite is not always static, sometimes it moves randomly
and the antenna pointing of satellite is harder to achieve line of sight
communication to other satellite when it is outage by tumbling effect. In order
to determine an appropriate direction of satellite antenna in inter-satellite
link, this paper analyze estimation performance of the direction of arrival
(DoA) using MUSIC algorithm from connected satellite signal source. It differs
from optical measurement, magnetic field measurement, inertial measurement, and
global positioning system (GPS) attitude determination. The proposed method is
characterized by taking signal source from connected satellites, after that the
main satellite processed the information to obtain connected satellites antenna
direction. The simulation runs only on the direction of azimuth. The simulation
result shows that MUSIC algorithm processing time is faster than satellite
movement time in orbit on altitude of 830 km with the period of 101 minutes.
With the use of a 50 elements array antenna in spacing of 0.5 wavelength, the
total of 20 angle of arrival (AoA) can be detected in 0.98 seconds of
processing time when using MUSIC algorithm.

21 Oct 2024
Self-Admitted Technical Debt (SATD) refers to circumstances where developers
use textual artifacts to explain why the existing implementation is not
optimal. Past research in detecting SATD has focused on either identifying SATD
(classifying SATD items as SATD or not) or categorizing SATD (labeling
instances as SATD that pertain to requirement, design, code, test debt, etc.).
However, the performance of these approaches remains suboptimal, particularly
for specific types of SATD, such as test and requirement debt, primarily due to
extremely imbalanced datasets. To address these challenges, we build on earlier
research by utilizing BiLSTM architecture for the binary identification of SATD
and BERT architecture for categorizing different types of SATD. Despite their
effectiveness, both architectures struggle with imbalanced data. Therefore, we
employ a large language model data augmentation strategy to mitigate this
issue. Furthermore, we introduce a two-step approach to identify and categorize
SATD across various datasets derived from different artifacts. Our
contributions include providing a balanced dataset for future SATD researchers
and demonstrating that our approach significantly improves SATD identification
and categorization performance compared to baseline methods.

19 Dec 2024
Classical simulations of quantum circuits are essential for verifying and
benchmarking quantum algorithms, particularly for large circuits, where
computational demands increase exponentially with the number of qubits. Among
available methods, the classical simulation of quantum circuits inspired by
density functional theory -- the so-called QC-DFT method, shows promise for
large circuit simulations as it approximates the quantum circuits using
single-qubit reduced density matrices to model multi-qubit systems. However,
the QC-DFT method performs very poorly when dealing with multi-qubit gates. In
this work, we introduce a novel CNOT "functional" that leverages neural
networks to generate unitary transformations, effectively mitigating the
simulation errors observed in the original QC-DFT method. For random circuit
simulations, our modified QC-DFT enables efficient computation of single-qubit
marginal measurement probabilities, or single-qubit probability (SQPs), and
achieves lower SQP errors and higher fidelities than the original QC-DFT
method. Despite some limitations in capturing full entanglement and joint
probability distributions, we find potential applications of SQPs in simulating
Shor's and Grover's algorithms for specific solution classes. These findings
advance the capabilities of classical simulations for some quantum problems and
provide insights into managing entanglement and gate errors in practical
quantum computing.

11 Nov 2024
Phishing attacks remain a persistent threat to online security, demanding robust detection methods. This study investigates the use of machine learning to identify phishing URLs, emphasizing the crucial role of feature selection and model interpretability for improved performance. Employing Recursive Feature Elimination, the research pinpointed key features like "length_url," "time_domain_activation" and "Page_rank" as strong indicators of phishing attempts. The study evaluated various algorithms, including CatBoost, XGBoost, and Explainable Boosting Machine, assessing their robustness and scalability. XGBoost emerged as highly efficient in terms of runtime, making it well-suited for large datasets. CatBoost, on the other hand, demonstrated resilience by maintaining high accuracy even with reduced features. To enhance transparency and trustworthiness, Explainable AI techniques, such as SHAP, were employed to provide insights into feature importance. The study's findings highlight that effective feature selection and model interpretability can significantly bolster phishing detection systems, paving the way for more efficient and adaptable defenses against evolving cyber threats
There are no more papers matching your filters at the moment.
