
18 Sep 2025
A generalization of the coadjoint orbit action describes the dynamics of an observer (or instrument). We consider how this fits in with the view of observables in field theory being correlations of read-outs of instruments and show how one recovers the usual -matrix formulae. A simple resolution of the Fermi paradox is also pointed out.

01 Oct 2025
Vision Language Models (VLMs) excel at identifying and describing objects but often fail at spatial reasoning. We study why VLMs, such as LLaVA, underutilize spatial cues despite having positional encodings and spatially rich vision encoder features. Our analysis reveals a key imbalance: vision token embeddings have much larger norms than text tokens, suppressing LLM's position embedding. To expose this mechanism, we developed three interpretability tools: (1) the Position Sensitivity Index, which quantifies reliance on token order, (2) the Cross Modality Balance, which reveals attention head allocation patterns, and (3) a RoPE Sensitivity probe, which measures dependence on rotary positional embeddings. These tools uncover that vision tokens and system prompts dominate attention. We validated our mechanistic understanding through targeted interventions that predictably restore positional sensitivity. These findings reveal previously unknown failure modes in multimodal attention and demonstrate how interpretability analysis can guide principled improvements.

14 Sep 2025


Generating high-quality 360° panoramic videos remains a significant challenge due to the fundamental differences between panoramic and traditional perspective-view projections. While perspective videos rely on a single viewpoint with a limited field of view, panoramic content requires rendering the full surrounding environment, making it difficult for standard video generation models to adapt. Existing solutions often introduce complex architectures or large-scale training, leading to inefficiency and suboptimal results. Motivated by the success of Low-Rank Adaptation (LoRA) in style transfer tasks, we propose treating panoramic video generation as an adaptation problem from perspective views. Through theoretical analysis, we demonstrate that LoRA can effectively model the transformation between these projections when its rank exceeds the degrees of freedom in the task. Our approach efficiently fine-tunes a pretrained video diffusion model using only approximately 1,000 videos while achieving high-quality panoramic generation. Experimental results demonstrate that our method maintains proper projection geometry and surpasses previous state-of-the-art approaches in visual quality, left-right consistency, and motion diversity.

21 May 2014

Convolutional Neural Networks are extremely efficient architectures in image
and audio recognition tasks, thanks to their ability to exploit the local
translational invariance of signal classes over their domain. In this paper we
consider possible generalizations of CNNs to signals defined on more general
domains without the action of a translation group. In particular, we propose
two constructions, one based upon a hierarchical clustering of the domain, and
another based on the spectrum of the graph Laplacian. We show through
experiments that for low-dimensional graphs it is possible to learn
convolutional layers with a number of parameters independent of the input size,
resulting in efficient deep architectures.

23 Apr 2021

This paper investigates the energy levels of two interacting charged particles in a uniform magnetic field, specifically modeling one charged and one neutral particle with a zero-range interaction. It determines the full spectrum analytically, revealing that the ground state remains bound for arbitrarily strong fields while excited states disappear above critical field strengths, and provides a simple formula for the number of bound states: N = 2/b + 3/2. This work offers an analytical framework that complements recent Lattice QCD results on light nuclei in extreme magnetic fields.

13 Oct 2025
A theoretical investigation into SU(N) ferromagnets where elementary magnets transform under the adjoint representation reveals two distinct ferromagnetic phases and a complex, N-dependent phase diagram. The research specifically identifies the spontaneous breaking of an additional discrete conjugation symmetry in one of these ferromagnetic phases.

04 May 2025

A multi-agent framework called DriveAgent combines LLM-based reasoning with multimodal sensor fusion (camera, LiDAR, GPS, IMU) for autonomous driving, achieving 89.96% precision in object detection and enhanced environmental understanding through specialized agents for perception, reasoning, and decision-making across diverse driving scenarios.

10 Oct 2024
Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.

02 Oct 2025
We introduce Policy Gradient Guidance (PGG), a simple extension of classifier-free guidance from diffusion models to classical policy gradient methods. PGG augments the policy gradient with an unconditional branch and interpolates conditional and unconditional branches, yielding a test-time control knob that modulates behavior without retraining. We provide a theoretical derivation showing that the additional normalization term vanishes under advantage estimation, leading to a clean guided policy gradient update. Empirically, we evaluate PGG on discrete and continuous control benchmarks. We find that conditioning dropout-central to diffusion guidance-offers gains in simple discrete tasks and low sample regimes, but dropout destabilizes continuous control. Training with modestly larger guidance () consistently improves stability, sample efficiency, and controllability. Our results show that guidance, previously confined to diffusion policies, can be adapted to standard on-policy methods, opening new directions for controllable online reinforcement learning.

26 Sep 2025
In this paper, we introduce a combination of novel and exciting tasks: the solution and generation of linguistic puzzles. We focus on puzzles used in Linguistic Olympiads for high school students. We first extend the existing benchmark for the task of solving linguistic puzzles. We explore the use of Large Language Models (LLMs), including recent state-of-the-art models such as OpenAI's o1, for solving linguistic puzzles, analyzing their performance across various linguistic topics. We demonstrate that LLMs outperform humans on most puzzles types, except for those centered on writing systems, and for the understudied languages. We use the insights from puzzle-solving experiments to direct the novel task of puzzle generation. We believe that automating puzzle generation, even for relatively simple puzzles, holds promise for expanding interest in linguistics and introducing the field to a broader audience. This finding highlights the importance of linguistic puzzle generation as a research task: such puzzles can not only promote linguistics but also support the dissemination of knowledge about rare and understudied languages.
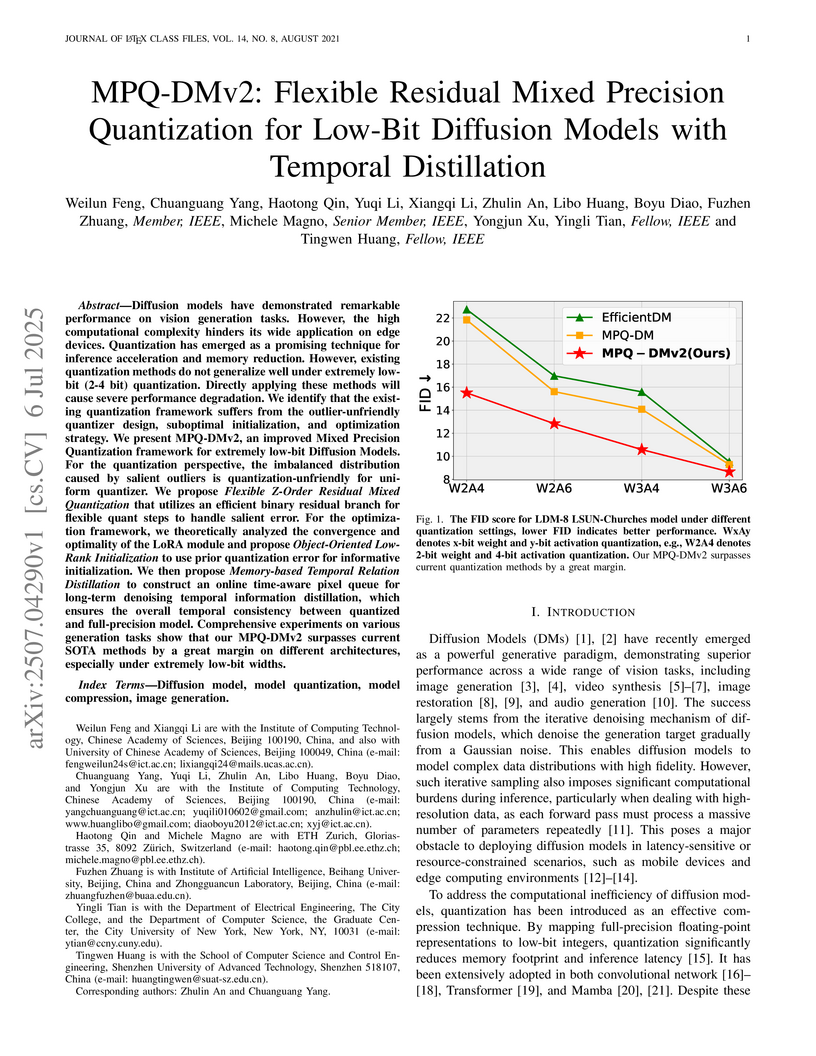
06 Jul 2025



Diffusion models have demonstrated remarkable performance on vision generation tasks. However, the high computational complexity hinders its wide application on edge devices. Quantization has emerged as a promising technique for inference acceleration and memory reduction. However, existing quantization methods do not generalize well under extremely low-bit (2-4 bit) quantization. Directly applying these methods will cause severe performance degradation. We identify that the existing quantization framework suffers from the outlier-unfriendly quantizer design, suboptimal initialization, and optimization strategy. We present MPQ-DMv2, an improved \textbf{M}ixed \textbf{P}recision \textbf{Q}uantization framework for extremely low-bit \textbf{D}iffusion \textbf{M}odels. For the quantization perspective, the imbalanced distribution caused by salient outliers is quantization-unfriendly for uniform quantizer. We propose \textit{Flexible Z-Order Residual Mixed Quantization} that utilizes an efficient binary residual branch for flexible quant steps to handle salient error. For the optimization framework, we theoretically analyzed the convergence and optimality of the LoRA module and propose \textit{Object-Oriented Low-Rank Initialization} to use prior quantization error for informative initialization. We then propose \textit{Memory-based Temporal Relation Distillation} to construct an online time-aware pixel queue for long-term denoising temporal information distillation, which ensures the overall temporal consistency between quantized and full-precision model. Comprehensive experiments on various generation tasks show that our MPQ-DMv2 surpasses current SOTA methods by a great margin on different architectures, especially under extremely low-bit widths.

14 Jun 2012
Lecture notes for the minicourse "Holonomy Groups in Riemannian geometry", a
part of the XVII Brazilian School of Geometry, to be held at UFAM (Amazonas,
Brazil), in July of 2012.

21 Apr 2025

Researchers from the University of Pennsylvania, City University of New York, and UC Berkeley introduced Mood Space, a framework that allows users to express abstract visual concepts through example images. This approach creates a structured latent space, enabling intuitive control for generating and manipulating images with smooth interpolations and consistent visual analogies.

25 May 2024


Although the performance of Temporal Action Segmentation (TAS) has improved in recent years, achieving promising results often comes with a high computational cost due to dense inputs, complex model structures, and resource-intensive post-processing requirements. To improve the efficiency while keeping the performance, we present a novel perspective centered on per-segment classification. By harnessing the capabilities of Transformers, we tokenize each video segment as an instance token, endowed with intrinsic instance segmentation. To realize efficient action segmentation, we introduce BaFormer, a boundary-aware Transformer network. It employs instance queries for instance segmentation and a global query for class-agnostic boundary prediction, yielding continuous segment proposals. During inference, BaFormer employs a simple yet effective voting strategy to classify boundary-wise segments based on instance segmentation. Remarkably, as a single-stage approach, BaFormer significantly reduces the computational costs, utilizing only 6% of the running time compared to state-of-the-art method DiffAct, while producing better or comparable accuracy over several popular benchmarks. The code for this project is publicly available at this https URL.

30 Jan 2025
The goal of this work was to develop a deep network for whole-head segmentation, including clinical MRIs with abnormal anatomy, and compile the first public benchmark dataset for this purpose. We collected 91 MRIs with volumetric segmentation labels for a diverse set of human subjects (4 normal, 32 traumatic brain injuries, and 57 strokes). These clinical cases are characterized by extended cerebrospinal fluid (CSF) in regions normally containing the brain. Training labels were generated by manually correcting initial automated segmentations for skin/scalp, skull, CSF, gray matter, white matter, air cavity, and extracephalic air. We developed a MultiAxial network consisting of three 2D U-Net models that operate independently in sagittal, axial, and coronal planes and are then combined to produce a single 3D segmentation. The MultiAxial network achieved test-set Dice scores of 0.88 (median plus-minus 0.04). For brain tissue, it significantly outperforms existing brain segmentation methods (MultiAxial: 0.898 plus-minus 0.041, SynthSeg: 0.758 plus-minus 0.054, BrainChop: 0.757 plus-minus 0.125). The MultiAxial network gains in robustness by avoiding the need for coregistration with an atlas. It performed well in regions with abnormal anatomy and on images that have been de-identified. It enables more robust current flow modeling when incorporated into ROAST, a widely-used modeling toolbox for transcranial electric stimulation. We are releasing a state-of-the-art model for whole-head MRI segmentation, along with a dataset of 61 clinical MRIs and training labels, including non-brain structures. Together, the model and data may serve as a benchmark for future efforts.

10 Nov 2024
Conventional computer vision models rely on very deep, feedforward networks processing whole images and trained offline with extensive labeled data. In contrast, biological vision relies on comparatively shallow, recurrent networks that analyze sequences of fixated image patches, learning continuously in real-time without explicit supervision. This work introduces a vision network inspired by these biological principles. Specifically, it leverages a joint embedding predictive architecture incorporating recurrent gated circuits. The network learns by predicting the representation of the next image patch (fixation) based on the sequence of past fixations, a form of self-supervised learning. We show mathematical and empirically that the training algorithm avoids the problem of representational collapse. We also introduce \emph{Recurrent-Forward Propagation}, a learning algorithm that avoids biologically unrealistic backpropagation through time or memory-inefficient real-time recurrent learning. We show mathematically that the algorithm implements exact gradient descent for a large class of recurrent architectures, and confirm empirically that it learns efficiently. This paper focuses on these theoretical innovations and leaves empirical evaluation of performance in downstream tasks, and analysis of representational similarity with biological vision for future work.

27 Mar 2025

This Technical Note presents a simple control approach for global trajectory tracking and formation control of underactuated surface vessels equipped with only two propellers. The control approach exploits the inherent cascaded structure of the vehicle dynamics and is divided into control designs at the kinematics and kinetics levels. A controller with a low-gain feature is designed at the kinematics level by incorporating the cascaded system method, persistency of excitation, and the small-gain theorem. Furthermore, a PD+ controller is designed to achieve the velocity tracking at the kinetics level. The proposed control laws are partially linear and saturated linear and easy to implement. Based on a leader-follower scheme, our control approach applies to the formation tracking control problem of multi-vehicle systems under a directed spanning tree topology. Our main results guarantee uniform global asymptotic stability for the closed-loop system, which implies robustness with respect to bounded disturbances in the sense of Malkin's total stability, also known as local input-to-state stability.

26 Sep 2025
In this paper, we introduce a combination of novel and exciting tasks: the solution and generation of linguistic puzzles. We focus on puzzles used in Linguistic Olympiads for high school students. We first extend the existing benchmark for the task of solving linguistic puzzles. We explore the use of Large Language Models (LLMs), including recent state-of-the-art models such as OpenAI's o1, for solving linguistic puzzles, analyzing their performance across various linguistic topics. We demonstrate that LLMs outperform humans on most puzzles types, except for those centered on writing systems, and for the understudied languages. We use the insights from puzzle-solving experiments to direct the novel task of puzzle generation. We believe that automating puzzle generation, even for relatively simple puzzles, holds promise for expanding interest in linguistics and introducing the field to a broader audience. This finding highlights the importance of linguistic puzzle generation as a research task: such puzzles can not only promote linguistics but also support the dissemination of knowledge about rare and understudied languages.

24 Jan 2019

In this paper we present a deterministic polynomial time algorithm for testing if a symbolic matrix in non-commuting variables over is invertible or not. The analogous question for commuting variables is the celebrated polynomial identity testing (PIT) for symbolic determinants. In contrast to the commutative case, which has an efficient probabilistic algorithm, the best previous algorithm for the non-commutative setting required exponential time (whether or not randomization is allowed). The algorithm efficiently solves the "word problem" for the free skew field, and the identity testing problem for arithmetic formulae with division over non-commuting variables, two problems which had only exponential-time algorithms prior to this work.
The main contribution of this paper is a complexity analysis of an existing algorithm due to Gurvits, who proved it was polynomial time for certain classes of inputs. We prove it always runs in polynomial time. The main component of our analysis is a simple (given the necessary known tools) lower bound on central notion of capacity of operators (introduced by Gurvits). We extend the algorithm to actually approximate capacity to any accuracy in polynomial time, and use this analysis to give quantitative bounds on the continuity of capacity (the latter is used in a subsequent paper on Brascamp-Lieb inequalities).
Symbolic matrices in non-commuting variables, and the related structural and algorithmic questions, have a remarkable number of diverse origins and motivations. They arise independently in (commutative) invariant theory and representation theory, linear algebra, optimization, linear system theory, quantum information theory, approximation of the permanent and naturally in non-commutative algebra. We provide a detailed account of some of these sources and their interconnections.

26 Apr 2025

We propose a framework for topological quantum computation using newly
discovered non-semisimple analogs of topological quantum field theories in 2+1
dimensions. These enhanced theories offer more powerful models for quantum
computation. The conventional theory of Ising anyons, which is believed to
describe excitations in the fractional quantum Hall state, is not
universal for quantum computation via braiding of quasiparticles. However, we
show that the non-semisimple theory introduces new anyon types that extend the
Ising framework. By adding just one new anyon type, universal quantum
computation can be achieved through braiding alone. This result opens new
avenues for realizing fault-tolerant quantum computing in topologically ordered
systems.
There are no more papers matching your filters at the moment.
